
January 12, 2017
Big Data Cluster in Shared Nothing Architecture in Leipzig
ScaDS.AI Dresden/Leipzig
The state of Saxony funded a notable shared nothing cluster located at the Leipzig University and the TU Dresden. Here we want to give a short overview on this new “Galaxy” cluster which is a very nice asset for ScaDS. Shared nothing is probably the most referenced architecture when talking about Big Data. The idea behind this cluster architecture is to use large amounts of commodity hardware to store and analyze big amounts of data in a highly distributed, scalable and cost effective way. It is optimized for massive parallel data oriented computations using e.g. Apache Hadoop, Apache Spark or Apache Flink.
Cluster Facts Overview
| Architecture | shared nothing |
| Number of servers | 90 (30 located in Dresden, 60 in Leipzig) |
| CPUs | 180 sockets, 1080 computing cores |
| Harddrives | 540 SATA discs, >2 petabyte in total |
| RAM | >11.5 terabyte |
| Network | 10 gigabit/s Ethernet |
The Galaxy Cluster consists of 90 servers of which 30 are located in Dresden and 60 in Leipzig and is managed by the Leipzig University Computing Center. As there is a high diversity of researchers requirements, the cluster is organized with respect to its size in quite a flexible way. Different computing partitions can be organized and managed depending on scientists’ needs. Thus Galaxy offers our Big Data scientists a very powerful computing and research environment. It is an important building block and good fit in combination with the other computing options available at ScaDS.

Galaxy Hardware
Common Hardware Recommendations
Some older public sources on hardware recommendations are available in public, for example:
- Chapter 10 of the book “Hadoop – The definitive Guide” from Tom White (2015, 4. Ed., O’Reilly)
- Cluster Planning Guide” in the documentation for Hortonworks HDP 2.4
Most guides go more into detail, e.g. make a distinction between compute and storage/IO intensive work load, but here is just a very brief summary:
- master nodes need more reliability, slave/worker nodes less
- 1-2 sockets witch 4-8 cores each and medium clock speed
- 32-512 gigabyte ECC RAM
- 4-24 hard disks with 2-4 terabyte each and SATA or SAS interface.
- 1-10 gigabit/s Ethernet
The Actual Hardware of Galaxy
For our Big Data cluster Galaxy we decided, as mentioned before, to go for the shared nothing architecture. Special focus was put on a big number of nodes and high flexibility for the high diversity of researchers needs. A Europe wide tender procedure got us good cluster hardware:
90 Nodes with the following homogeneous hardware specification:
- 2 sockets equipped with 6 Core CPUs (Intel Xeon E5-2620 v3, 2.4 GHz, supports Hyperthreading)
- 128GB RAM (DDR4, ECC)
- 6 SATA Hard disks with 4 terabyte each
- attached via a controller capable of JBOD (recommended for Apache HDFS) or fault tolerant RAID 6 configuration
- 10 gigabit/s Ethernet interface
In addition to that we have a dedicated virtualization infrastructure. There we can organize management nodes and master nodes in as many virtual machines as needed. They benefit from better protection against hardware failures but can leverage only limited resources in comparison with a dedicated server.
Network Infrastructure
The Big Data cluster spans both ScaDS partner locations, Dresden and Leipzig. 30 of the 90 Nodes are located at the TU Dresden, 60 Nodes and the management infrastructure is located at the Leipzig University. The nodes of both locations are organized in a common private network, connected transparently via a VPN tunnel. To achieve optimal performance on this tunnel, the VPN tunnel endpoints on both sides are specialized routers with hardware support for the VPN packaging. The Ethernet-bandwidth within each location is 10 gigabit/s via non-blocking switches. For security reasons the cluster’s private network is accessible only from the network of the Leipzig University. Scientists from other institutions with a project on the Big Data infrastructure are currently provided with a VPN-Login when needed. he Galaxy cluster consists of 90 worker nodes plus virtualization infrastructure plus network infrastructure to interconnect the two locations transparently.
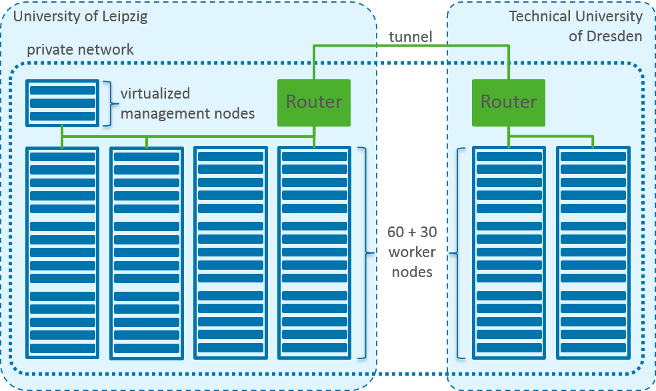
Galaxy Infrastructure
Management via Foreman and Puppet
Managing a cluster of this size is quite complex and separate installation no longer an option. It would be too much manual work with too many possible errors or inconsistent configurations. For the Galaxy cluster we utilize the system life cycle management tool Foreman in combination with Puppet as configuration management. Foreman supports us with the automated system installation configured via template files and the management infrastructure for Puppet. Puppet clients on the worker nodes check in with the Foreman server for updated Puppet modules, where we can describe more specific node configuration.
Disk Partitioning
One thing we define in Foreman is the hard disk partitions and mount options for the worker nodes. We use XFS and ZFS as local filesystem, both are quite mature and support very large files and storage volumes. Currently we defined the following partitions for optimal flexibility:
| Mount point | Hard disks | Filesystem | Size | Comment |
|---|---|---|---|---|
| root and several other directories | HD 1 | XFS | ~0,5 TB | |
| /home | HD 1 | XFS | 3,5 TB | |
| /scratch_zfsvol | HD 2-6 | ZFS | ~7 TB | sw raid 6 via ZFS, used as big scratch directory |
| /scratch/hdfs[1-5] | HD 2-6 | XFS | 5x ~2 TB | optimized for Apache Hadoops HDFS storage |
Login Management
We use a dedicated login database to enable access to the Big Data cluster in Leipzig for scientists from several research locations in Saxony and the near vicinity. This database for scientific computing logins is separated from Leipzig University’s login database. Researcher can register for a scientific computing login via a management portal, using the DFN AAI authentication and authorization service. At the same management portal one can reset ones password. Technically those scientific computing logins are stored in an Active Directory and each worker node is connected to it using the SSSD package.
Gateway
The gateway node is a special node as public entry point to the cluster. Typical tasks handled at the gateway node at a secure shell (SSH) are
- data transfer to or from the cluster
- job commit
- access to job subsystems for progress or error information
- direct login to a used worker node
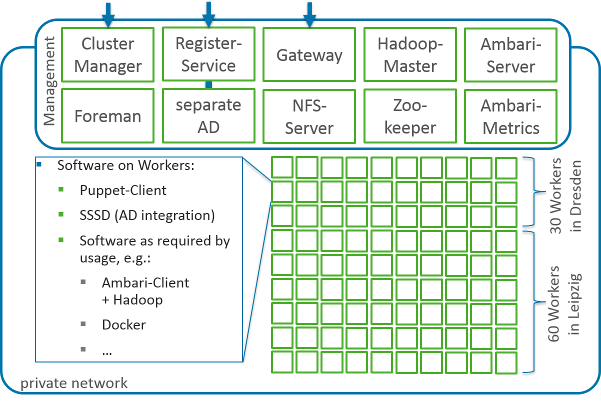
For the galaxy cluster quite a lot of management and master components are needed as well as some basic software on each worker node. The Cluster Manager, Register Service and Gateway is interacting with the outside. The Cluster Manager is introduced later in this article.
Overview on Galaxy Operations Concept
Diversity of Scientists Needs
There is a high diversity in software and requirements of Big Data scientists, similar to the broad field of Big Data research and software frameworks used in the field. In our experience just an Apache Hadoop cluster does not fit all. Only a small part of the researchers computing demand can be queued as an Apache Hadoop batch job. Often scientists need quite specific software, at times with specific software versions or configurations that conflict the ones required by other scientists. Sometimes they want to get performance benchmarks on a dedicated specific cluster environment.
Cluster Partitioning as Solution
Our approach to tackle this problem of diversity is to divide the cluster as needed into cluster partitions. Each partition can be equipped with different software and configuration. Each partition can be seen as smaller (sub) cluster with a subset of designated worker nodes. Worker nodes can get reassigned to new or other clusters when the requirements or reservations shift. Some of the cluster software seen so far is even capable of accepting or decommissioning nodes during operation. Examples for this are the decommissioning feature of Apache Hadoop or the node removal in Slurm.
Of course cluster partitioning has it’s downsides as well. Probably the main one is suboptimal cluster utilization because shifting partitions not fast or fine granular enough. But currently we see no alternative. As far as we know there is no cluster scheduler capable of hosting most of the Big Data software without configurational or performance drawbacks.
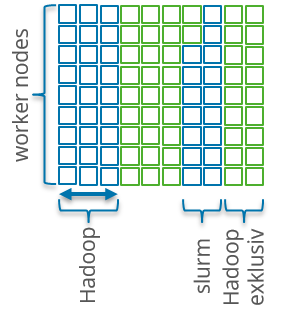
For the galaxy cluster quite a lot of management and master components are needed as well as some basic software on each worker node. The Cluster Manager, Register Service and Gateway is interacting with the outside. The Cluster Manager is introduced later in this article.
Practical Cluster Partitioning
For practical cluster partitioning the usage of Foreman + Puppet as management software helps us again. We can utilize the management software to reconfigure cluster nodes or even get fresh installed nodes when needed. But only a whole node is the finest cluster granularity so far. And reconfiguration and data transfer for the addition and removal of nodes take quite some time. Therefore, we try to limit the amount of partition shifting by recommending cluster reservation time to be something between a couple of days and a couple of weeks, depending on the scientist’s requirements, the partition’s size and cluster utilization.
Cluster Partition Types
At Galaxy we support the following partition and usage types:
- Apache Hadoop Batch Job: Submission of batch jobs in a cluster shared with other users. Apache Flink or Apache Spark Jobs can be run on this partition as well as both frameworks support running on Hadoops scheduler YARN.
- Apache Hadoop Exclusive Partition: Reserved Partition with Apache Hadoop dedicated for one user or user group.
- Exclusive Flexible Partition: Reserved partition individually configured and dedicated for one user or user group. Realized either via Puppet, manual configuration or with Docker containers.
- Slurm Batch Jobs (coming soon): With the Slurm scheduler some Big Data tasks not compatible with Apache Hadoop can get scheduled without the need for a dedicated flexible partition.
For the future we consider supporting e.g. Apache Mesos batch jobs or OpenStack as well.
Cluster Manager
The cluster manager helps us with organizing the cluster partitions and the scientists’ usage of them. This part of the cluster is still under development. As a first step a calendar with web GUI is realized where we can track reservations for partition usage and transform them to users’ access rights. In future versions the cluster manager could automate the cluster partition resizing, creation and removal.
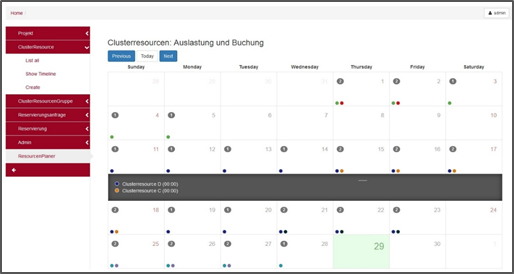
Usage and Outlook
The cluster Galaxy at Leipzig University is optimized for Big Data research on a shared nothing architecture. It supports a broad diversity of usage through its flexible partitioning approach, including efficient Hadoop job scheduling and dedicated temporary partitions configured according to the user’s need.
Access to Galaxy
The Galaxy cluster is available for scientists at universities in Saxony and the near vicinity. Cluster usage is organized as follows:
- contact us and we will discuss your requirements
- create an account at register.sc.uni-leipzig.de
- get your reservation for cluster ressources
- access the reserved resources during the reservation interval via SSH to our gateway
- do your research e.g. with Apache Hadoop jobs or on an exclusive cluster partition
- clean resources after usage
You can contact us at scadm@uni-leipzig.de or directly:
- Dr. Stefan Kühne (URZ Leipzig, Research/Development)
- Vadim Bulst (URZ Leipzig, Infrastructure)
- Lars-Peter Meyer (ScaDS Dresden Leipzig)
More Options
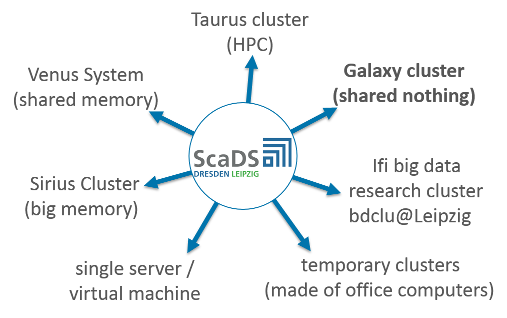
Although shared nothing is the cluster architecture most mentioned in the field of Big Data research and galaxy is quite an impressive one, we at ScaDS are happy to have more choices for deploying and testing:
Single Server / Virtual Machine
Sometimes a dedicated server or virtual machine is the best option.
Temporary Clusters
Especially temporary student projects build temporary shared nothing clusters out of small numbers of office pcs available.
IfI Big Data Research Cluster
This shared nothing cluster with 18 nodes is located at the computer science department (IfI) of the Leipzig University. This cluster is dedicated for flexible research and offers solid state discs beside normal hard discs as option for comparisons.
Galaxy Cluster
As described in this article the Galaxy cluster is equipped with about 2 petabyte storage capacity, about 2000 computing cores and in total about 11.5 terabyte RAM, organized in shared nothing architecture. Although tending to the production oriented side it offers quite a lot of flexibility with its partitioning concept.
Venus System
Venus is a shared memory computer located at the ZIH at the TU Dresden. It has 8 terabyte of RAM for 512 cpu cores and is organized with the linux batch job scheduler Slurm.
Sirius Cluster
The new Sirius Cluster with 2 shared memory computers is optimized for in memory databases. Each node is equipped with 6 terabyte RAM and 256 cores. The cluster is located at the Leipzig University Computing Center.
Taurus Cluster
The HPC cluster Taurus is located at the ZIH at the TU Dresden and is listed currently as number 107 in the Top500 List of supercomputers in the world from November 2016. More than 10 000 cores are organized with the linux batch job scheduler Slurm. The deployment of Apache Hadoop on Slurm is possible.



funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
