
October 17, 2016
Connecting Digital Humanities with CLARIN
Research
One of the questions that I am often confronted with when presenting my work is what my work has to do with Big Data, when the biggest text collections that I have to deal with fill only a couple of Gigabyes of hard disk space. Why am I asking myself that question? Many argue that Big Data has to have to do with large amounts of data. Furthermore, it is said that Big Data related problems have to deal with at least Tera- or Petabytes of stored information. As understandable as this argument is, there is actually a whole lot more to Big Data than just the size of a data set. With this article, I want to explain what it is as well as what CLARIN and CTS have to do with it.
Digital Humanities and the 4 Big V’s
Defining what Big Data is and what it is not is not a trivial task. IBM specified 4 terms that have to be considered when dealing with Big Data: Volume, Variety, Veracity and Velocity. Since they all start with the letter V, these terms are often referred to as the 4 V’s of Big Data. Volume corresponds to size-related data issues and is probably the easiest to understand. Veracity and Velocity describe how reliable data is and how fast it needs to be processed. Variety describes the heterogenity of data sources, data formats, metadata markup and tool – or workflow requirements of data sets. To be qualified as a Big Data problem, something has to be problematic in at least one of these aspects.
Since my work has to do with corrected text, Veracity and Velocity can be ignored. In general, texts are not streamed in problematic amounts and aside from automatic character recognition, the error potential for text is very small: a letter is either there or it is not. With all the digitization projects that are currently running, Volume might be problematic, but considering that even large text corpora like the Deutsche Textarchiv with 142015148 words in 2441 documents only require a couple of Gigabytes of hard disk space, it is hard to talk about a Volume problem. This leaves us with Variety that – in my opinion and experience – is the most prominent issue that has to be dealt with in text based Digital Humanities.
File Variety
Most data sets are generated using the guidelines that are specified by the tools that the data is built for. Audio and Video have to be stored in a specific way to be supported by media players, sensoric data is formated in a certain way to be interpretable by the surrounding workflows and even if no format is used, the text is really just transporting information based on a small set of rules. For text data, this is not the case. The text itself is the information and the complexity of the information that is described is theoretically unlimited. This results in a huge heterogenity of text formats because the tools that are used to create the files do not limit their content as long as it does not encode letters or other characters in a unknown way.
While cases exist in which PDFs that are generated from scanned JPG files are considered as digital documents, most digitized and edited documents from established text corpus projects can be used as plain text. Anything else – like for instance .odt, .doc or .pdf – is considered as not usable by at least me, which solves this variety problem in my working environment.
Markup Variety
Still, even after when limiting the data to plain text, the heterogenity of formats is huge because different researchers use different markup for the meta information. There is no universal guideline how to format text data because – again and contrary to for example HTML – text data does not have to be compliant to any tool. For instance, a headline in HTML is generally marked as < h1 > because any browser will know that this means that the following content has to be rendered in a certain way. Edited digital documents on the other hand are mostly incorporated in project specific workflows. This means that a headline may be marked as < h1 >if the documents are available as a website. It may also be < headline > or < title > or < ueberschrift > depending on the purpose of the file and the technical knowledge of the editor.
To limit this heterogenity, guidelines are established. To my knowledge, TEI/XML provides the most prominent markup guidelines for digitized documents and many current corpus projects provide at least an export functionality for TEI/XML. Documents in this format are divided into a TEIHeader with the meta information for this document and a body that contains the actual text. The body can be structured in several ways depending on the type of document – for example chapter|sentence or song|stanza|verse. Being based on XML, this format requires a certain technical knowledge and understanding of structure, but because of its expressiveness and the relative intuitive syntax of XML, TEI/XML is worth the learning effort.
The benefits of being compliant to established guidelines can for example easily be understood when looking at HTML. The markup of HTML can be interpreted by any web browser, which means that this combination of characters : < i > some text < / i > will be rendered as some text if the spaces between the characters are deleted. Without this common set of rules, it would not be possible to design websites aside from using ASCI art.
In the following images, this principle is applied to text by using generic rules to render the content of certain TEI/XML tags nicely. The upper image shows the TEI/XML markup as it would be shown in any plain text editor. The lower image shows the way that the tags are visualized in Martin Reckziegel’s CTRace.

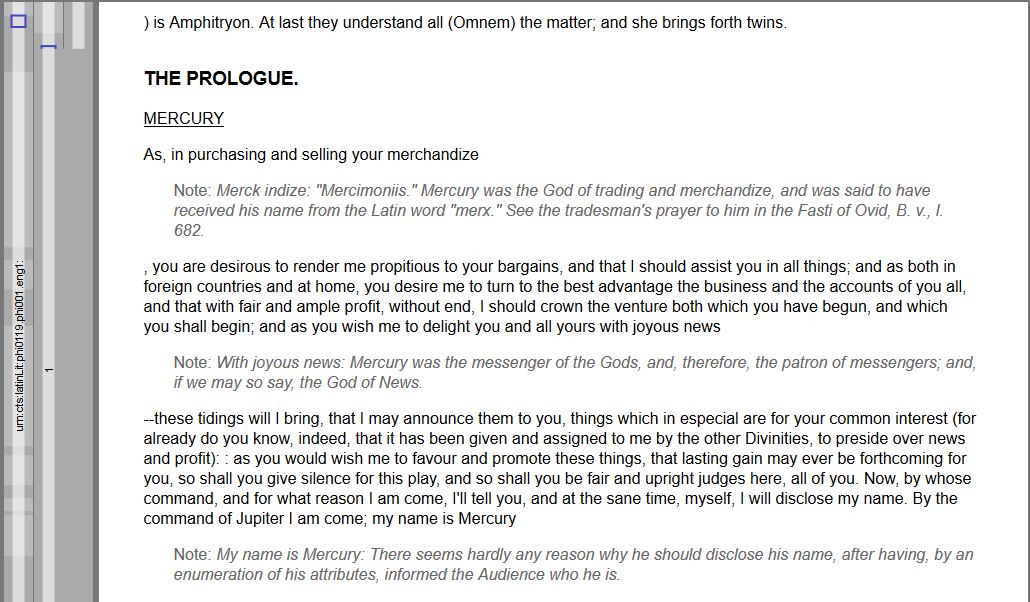
Similiar to how any HTML is rendered nicely in a browser, any TEI/XML document can be rendered nicely using tools that understand the markup. This way TEI/XML can serve as a very effective way to significantly reduce the markup Variety. One main disadvantage of XML is that its use can have a serious performance impact compared to a simple plain text format like CSV. Monica Berti kindly provided the following TEI/XML example use case:
An example of a project based on TEI/XML is the Open Greek and Latin (OGL) developed at the Leipzig Universit. The project is producing machine-corrected XML versions of ancient Greek and Latin works and translations. The goal is to provide at least one version for all Greek and Latin sources produced during antiquity (about 150 million words). Analysis of 10,000 books in Latin, downloaded from Archive.org, identified more than 200 million words of post-classical Latin. With 70,000 public domain books listed in the Hathi Trust as being in Ancient Greek or Latin, the amount of Greek and Latin already available will almost certainly exceed 1 billion words.
The project is using OCR-technology optimized for Classical Greek and Latin to create an open corpus that is reasonably comprehensive for the c. 100 million words produced through c. 600 CE and that begins to make available the billions of words produced after 600 CE in Greek and Latin that survive. OGL XML files are based on the EpiDoc guidelines and are CTS compliant.
Technical Variety
After dealing with the problem of file types by limiting the data to files that can be accessed with plain text editors and dealing with the problem of heterogenous file formats by limiting the data to TEI/XML, another more technical layer of heterogenity is becoming prominent: tools, workflows and data availability. Text data that is available online is generally offered in project specific websites, including GitHub repositories, Javascript applications, data dumps or HTML pages. Generally, whenever researchers want to access text data that is advertised as publicly available, it is at first required to learn, how and if the data can be accessed. Compiling a text corpus may even require to implement a specific crawler for a given project.
Tools and workflows are mostly developed to suit the project specific data set, which in many – if not most – cases results in individual tools for specific data sets that can not be applied to other projects.
An example of technical variety in the Digital Humanities is illustrated by two projects developed by Monica Berti at the Leipzig University. Project specific technical solutions have been italicized. From a technical point of view, these parts are probably exchangeable, which means that in an unrelated project, they might create the same information as a different kind of data.
Digital Fragmenta Historicorum Graecorum (DFHG)
The first one is the Digital Fragmenta Historicorum Graecorum (DFHG), which is the digital version of a print collection of quotations and text reuses of ancient Greek authors. The digital version has been produced starting from the OCR output of the print edition.
Combining manual work and shell scripts, an SQL database has been created for delivering web services and tools. The raw data files are inserted into the SQL DB enriched with information useful to perform searches and citation extraction (based on CTS and CITE URNs). Ajax web pages are automatically generated to increase the usability of DFHG data. The project exports data stored in the DFHG database in different formats: CSV format files and XML format files (EpiDoc compliant). Files are available on GitHub. An API can be queried with DFHG author names and text reuse numbers: the result is a JSON output containing every piece of information about the requested text reuse.
Integration with external resources allows to get inflected forms of DFHG words and lemmata from dictionaries and encyclopedias. An alignment of DFHG Greek text reuses and their Latin translations is available through the Parallel Alignment Browser developed at the Leipzig University.
Digital Athenaeus
The second project is the Digital Athenaeus, which is producing a digital edition of an ancient Greek work entitled the Deipnosophists by Athenaeus of Naucratis. The project is focused on annotating quotations and text reuses in order to provide an inventory of reused authors and works and implement a data model for identifying, analyzing, and citing uniquely instances of text reuse in the Deipnosophists.
In order to get these results, the project has produced an online converter for finding concordances between the numerations used in different editions of the Deipnosophists and get stable CTS URNs for citing the text. Moreover, digital versions of printed indexes have been created in order to map the text references to reused authors and works. Index entries can be visualized in Martin Reckziegel’s Canonical Text Reader and Citation Exporter (CTRaCE) developed at the University of Leipzig. The project has implemented two web-based interface tools for querying the SQL Database of the indexes. An API with JSON output allows to integrate index data into external services. Different file formats (CSV, XML, etc.) can be generated from the DB.
Technical Solutions
Both examples use different technical solutions including some that were implemented specifically for these projects. While standards and guidelines can be shared among research groups, project specific technical solutions – like scripts, format conversions and computer setups – are potentially hard to reuse in other projects by different research groups because of small deviations in the data or other requirements. That is why it is often more reasonable to build yet another project specific workflow even if problems overlap with an already existing solution. One step to solve this technical Variety is the developement of text research infrastructures like CLARIN because they enable researchers to outsource technical problems.
CLARIN
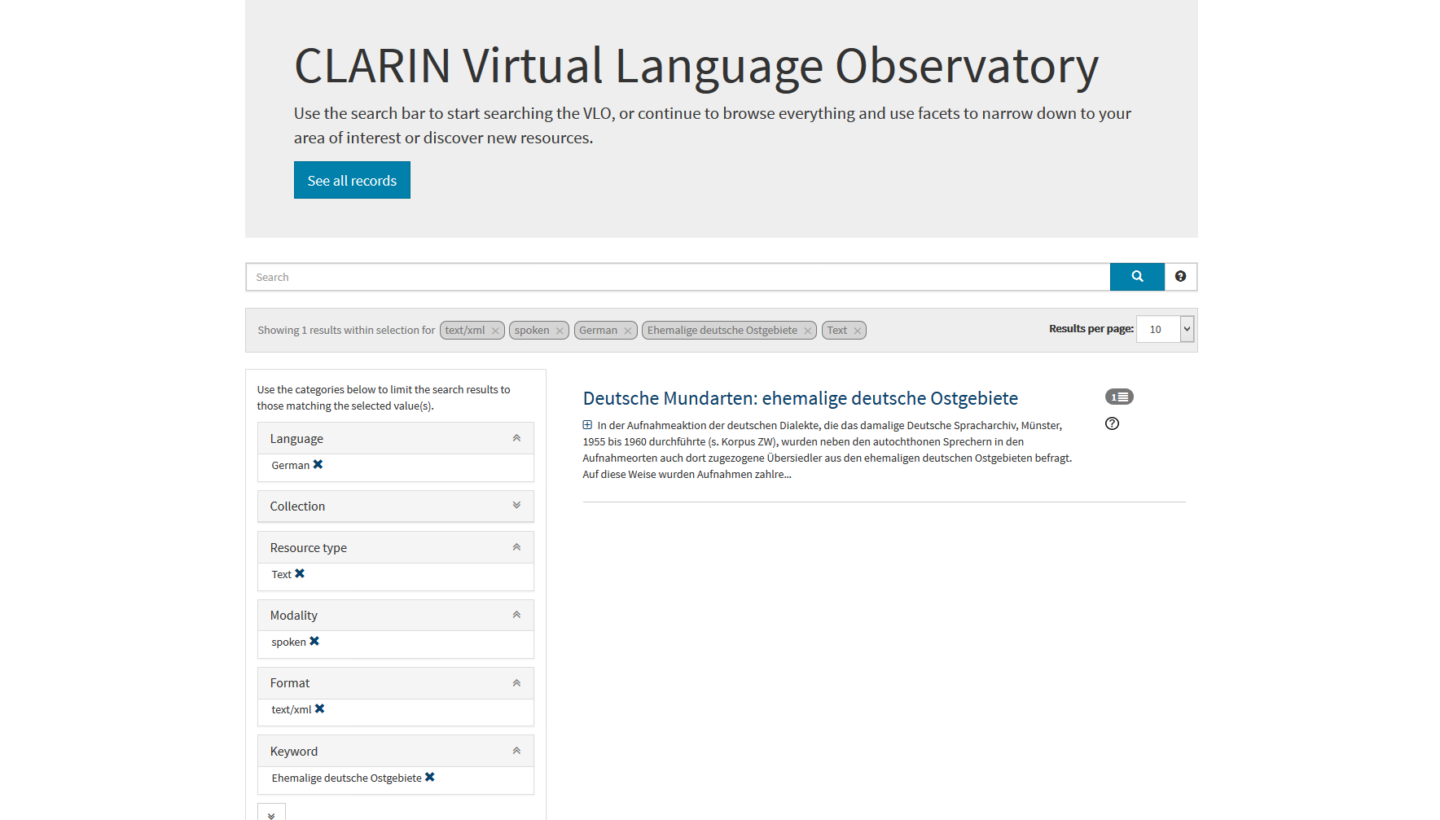
The Common Language Resources and Technology Infrastructure CLARIN is a european research infrastructure project with the goal to provide a huge interoperable research environment for researchers and is for example described in detail in “Was sind IT-basierte Forschungsinfrastrukturen für die Geistes- und Sozialwissenschaften und wie können sie genutzt werden?” by Gerhard Heyer, Thomas Eckart and Dirk Goldhahn. Generally, CLARIN combines the efforts of various research groups to build an interoperable set of tools, data sets and web based workflows. This interoperability enables facetted document search over several different servers of different research groups in the Virtual Language Observatory VLO. In this example, I use VLO to limit 904014 ressources on different servers to 1 german resource describing spoken language in XML markup.
Another great example of interoperability is WebLicht. “WebLicht is an execution environment for automatic annotation of text corpora. Linguistic tools such as tokenizers, part of speech taggers, and parsers are encapsulated as web services, which can be combined by the user into custom processing chains. The resulting annotations can then be visualized in an appropriate way, such as in a table or tree format. (…) By making these tools available on the web and by use of a common data format for storing the annotations, WebLicht provides a way to combine them into processing chains.”
The tools, webservices and data sets in CLARIN are added by various research groups, which – depending on the technical knowledge – can be a complex tasks. To bridge this potential gap in digitized documents, it requires some kind of common ground. It should be on the one hand strict and persistent enough to be used as an technical access point for the data transfer. On the other hand, it should suit the requirements that Humanists have on text ressources. This common ground is the Canonical Text Service protocol.
Canonical Text Service (CTS)
Developed by researchers with a humanistic background, the Canonical Text Service protocol (CTS) reflects the requirements that Digital Humanists have on a text reference system. The core idea is that – similiar to the URLs that are used to find individual websites – Unique Resource Names (URNs) are used to reference text passages persistently roughly following the hierarchical principle that is used in common citation: at first a group of documents is specified, then one document and then one text passage inside the document.
These URNs are then used to reference text via a web service, which basically means that every text passage can be persistently stored in the form of a web link or a bookmark in a web browser. Adding these links as citation reference enables readers to directly access the referenced text instead of having to run to the nearest library hoping that they own a copy of the referenced edition of the referenced book.
The protocol was developed by David Neel Smith and Christopher Blackwell in the Homer Multitext project. It was brought brought from the United States to Leipzig by Gregory Crane during the ESF project A Library of a Billion Words, a collaberation between the Leipzig University Library, the Natural Language Processing Group and the Visualisation department of Leipzigs Institute for Computer Science and the newly established Digital Humanities Institute. The goal was to create a workflow for a digital library and my task in this project was to set up a scalable implementation of CTS.
The exact specifications are available here. You can find the project website for the CTS in Leipzig here. The following examples hopefully illustrate the core mechanic of CTS URNs:
Static CTS URNs are used to reference text parts like chapters or sentences as in Document ( urn:cts:pbc:bible.parallel.eng.kingjames: ) or Verse ( urn:cts:pbc:bible.parallel.eng.kingjames:1.3.2 )
Dynamic CTS URNs using spans of URNs or sub passage notation allow to reference any possible text passage in a document as in Span of URNs ( urn:cts:pbc:bible.parallel.eng:1.2-1.5.6 ) or Sub passage notation (urn:cts:pbc:bible.parallel.eng:1.2@the[2]-1.5.6@five )
At the current state of implementation, the information from the TEI/XML document is directly translated into the corresponding information in CTS. What separates CTS from other reference systems for text – besides some technical advantages – is that creating this format for data sets is a research question in Digital Humanities itself. Researchers do not have to create these files to be able to connect to the tools but instead want to create instances of CTS to be able to reference text passages online as for example illustrated by mentions in the works of Philologist Stylianos Chronopoulos, Digital Humanist Monica Berti, humanistsic projects like Perseus and Croatiae Auctores and interesting, philosophical and sometimes heated discussions about various implications of CTS.
This self purpose of the protocol combined with the relatively strict technical specification makes it a prime candidate for a connection between the data sets in Digital Humanities and the tools and services provided by CLARIN.
Connecting the dots between CTS and CLARIN
By establishing CTS and incorporating it into existing infrastructures a fixed set of tools and workflows from Computer Scientists is combined with a text reference method that is used and useful in its own for Humanists. This way the heterogenity at the intersection of computing and the disciplines of the humanities is reduced – or to use the relevant technical terms – Variety in Digital Humanities is reduced.
And this is exactly what is happening. Before the end of this year, a joint effort of ScaDS and CLARIN Leipzig will result in a connection between CTS and CLARIN, providing a fine-granular reference system for CLARIN and opening its infrastructure for many Digital Humanists across the world. From there on, any research project (in Digital Humanities) that includes creating a CTS data set can automatically be incorporated in CLARIN. The corresponding work is presented at the CLARIN Annual Conference in 2016 and described in the paper Jochen Tiepmar, Thomas Eckart, Dirk Goldhahn und Christoph Kuras: Canonical Text Services in CLARIN – Reaching out to the Digital Classics and beyond. In: CLARIN Annual Conference 2016, 2016 .


funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
