März 27, 2025
Git-bob: Transparente und nachvollziehbare KI-Unterstützung für Code-Entwicklung in den Datenwissenschaften
ScaDS.AI Dresden/Leipzig
KI-generierter Code ist für viele Forschende eine große Unterstützung, birgt aber auch Risiken bezüglich Zuverlässigkeit, Nachvollziehbarkeit und Reproduzierbarkeit. Der KI-Assistent git-bob soll nun Datenwissenschaftler:innen eine niederschwellige Unterstützung bieten, um im Team gemeinsam mit KI Datenanalyse Code für die eigene Forschung zu generieren.
Wer für seine Forschung viel Programmcode schreiben muss, um Daten zu analysieren, hat es wahrscheinlich schon einmal ausprobiert: Fix einen Prompt in das Gen-KI-Modell der Wahl eingeben und sich schnell ein paar Absätze Computercode generieren lassen – und das oftmals nicht ohne Erfolg. KI-generierter Code sieht gut aus und liefert auch Ergebnisse. Ob diese Ergebnisse jedoch korrekt sind, und der Code das Richtige macht, sehen oft nur Experten auf Anhieb.

Je nachdem, wie der Prompt formuliert wurde, können KI-Modelle Schwierigkeiten haben, die Anforderungen eines Projekts vollständig zu verstehen, was zu unangemessenen oder ineffizienten Codevorschlägen führen kann. In manchen Datenanalyse-Projekten ist KI schon so weit eingedrungen, dass nicht mehr genau feststellbar ist, welche Teile des Codes von Menschen und welche Teile von KI geschrieben wurden. In solchen Fällen sind die Prinzipien der guten Wissenschaftlichen Praxis in Gefahr.
Nichtsdestotrotz bietet KI-gestütztes Programmieren ein enormes Potential, gerade für die Datenanalyse, findet Dr. Robert Haase von ScaDS.AI Dresden/Leipzig. Um dieses Potential besser für die Wissenschaft nutzbar zu machen, hat er die Plattform git-bob entwickelt. Dies ist ein Online-Tool mit dem Forschungsteams zusammen mit KI programmieren können, nachvollziehbar und transparent, eben im Sinne der Guten Wissenschaftlichen Praxis.
Programmieren für Datenanalyse mit KI-Assistenten git-bob
Für die Datenanalyse in Forschungsprojekten ist oft erheblicher Programmieraufwand erforderlich, um vielfältige Datensätze angemessen zu analysieren. Dabei programmieren Datenwissenschaftler:innen wiederholt sehr ähnlichen Code. Wenn dieser Code KI-generiert wird, lässt sich theoretisch sehr viel Zeit sparen. Wenn jedoch fehlerhafter Code Analysen verfälscht und aufwendige Fehlersuchen nach sich zieht, ist jeder Zeitvorteil verschenkt. Um sicherzustellen, dass das Programmierte auch in der Praxis hohe Qualität hat und Daten korrekt auswertet, orientierte Robert Haase den Code-Generierungsprozess der Plattform daran, wie Datenwissenschaftler:innen normalerweise zusammenarbeiten – in kollaborativen Feedbackschleifen.
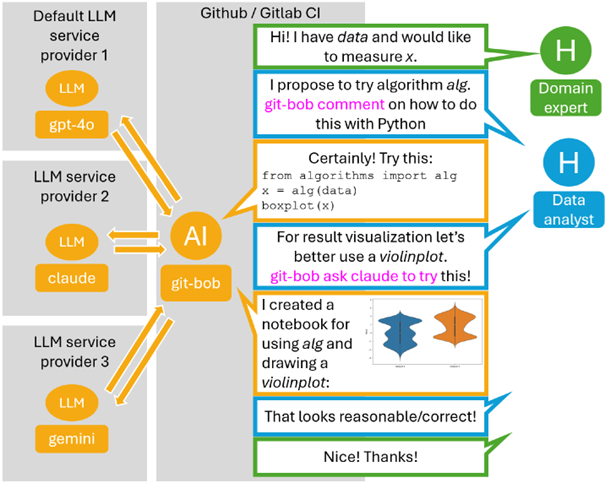
(Quelle: https://zenodo.org/records/14019030; CC-BY 4.0)
Durch git-bob können mehrere Forscher:innen mit verschiedenen KI-Systemen gemeinschaftlich an einem Projekt arbeiten und Programmcode schreiben. Dabei wird transparent dokumentiert, welche Teile des Codes von Menschen und welche von KI geschrieben wurden. So kann man sich direkt gegenseitig helfen, Feedback geben und den generierten Code von mehreren Augen überprüfen lassen. Hinweise für zielführende Prompt-Strategien müssen so nicht mehr informell zwischen Tür und Angel weitergegeben werden, sondern werden dokumentierter Teil des Feedbackloops.
Arbeiten mit git-bob
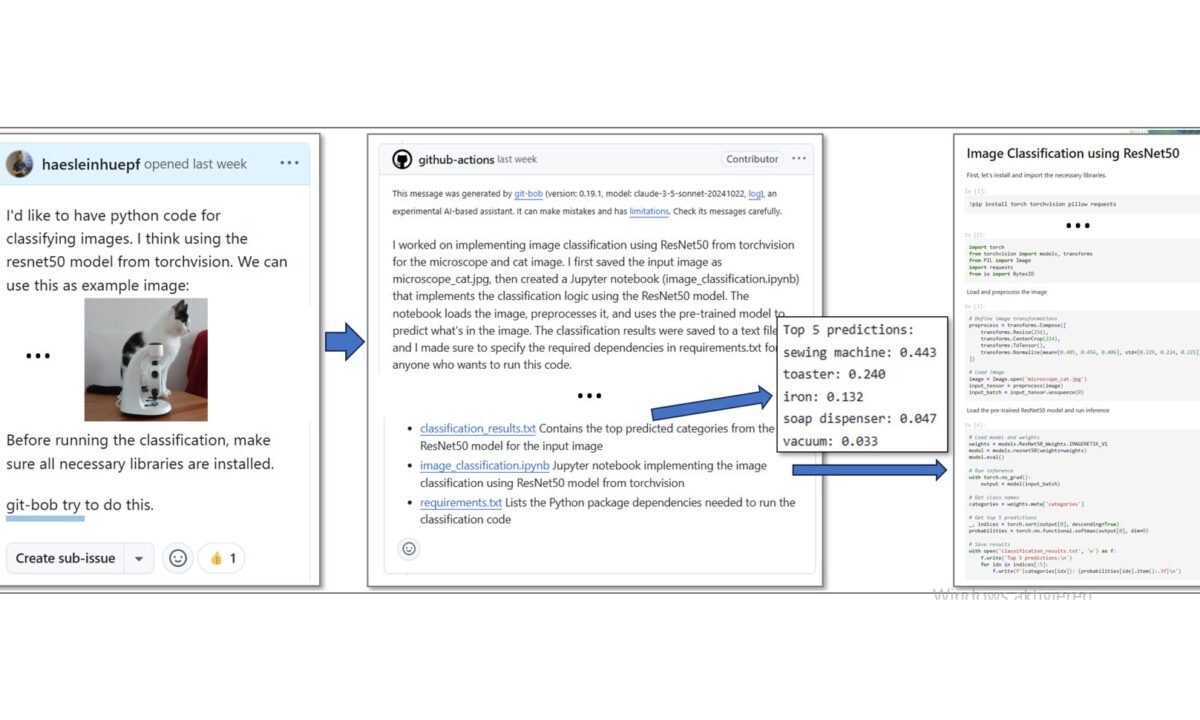
Die Arbeit mit git-bob beginnt typischerweise mit der Erstellung eines GitHub-Issues, in dem Forschende ihr Problem oder ihre Anfrage beschreiben. Ein Mitglied des jeweiligen Repositories kann dann git-bob beispielsweise mit Befehlen wie „git-bob comment on this“ oder „git-bob try to program this“ aktivieren. Der KI-Assistent antwortet dann mit Lösungsvorschlägen: Sowohl Codeauszüge wie auch Data-Visualisierungen. Nach dem initialen Output, wird die Ausgabe dann in einem iterativen Austausch zwischen Nutzer:innen und git-bob verfeinert. Die Plattform kann dabei auf zahlreiche große Sprachmodelle wie Anthropic’s Claude, OpenAI’s chatGPT, als auch Google’s Gemini zurückgreifen. Auf Wunsch kann git-bob die finale Lösung auch als Pull-Request einreichen, der dann von den Forschenden geprüft und genehmigt werden muss, bevor er implementiert werden kann. Alternativ kann git-bob auch Pull-Requests von Menschen kommentieren und Korrekturen in den bestehenden Code übernehmen. Alle Änderungenmüssen aber am Ende von einem Mensch akzeptieren und in die Code-Basis übernehmen werden.
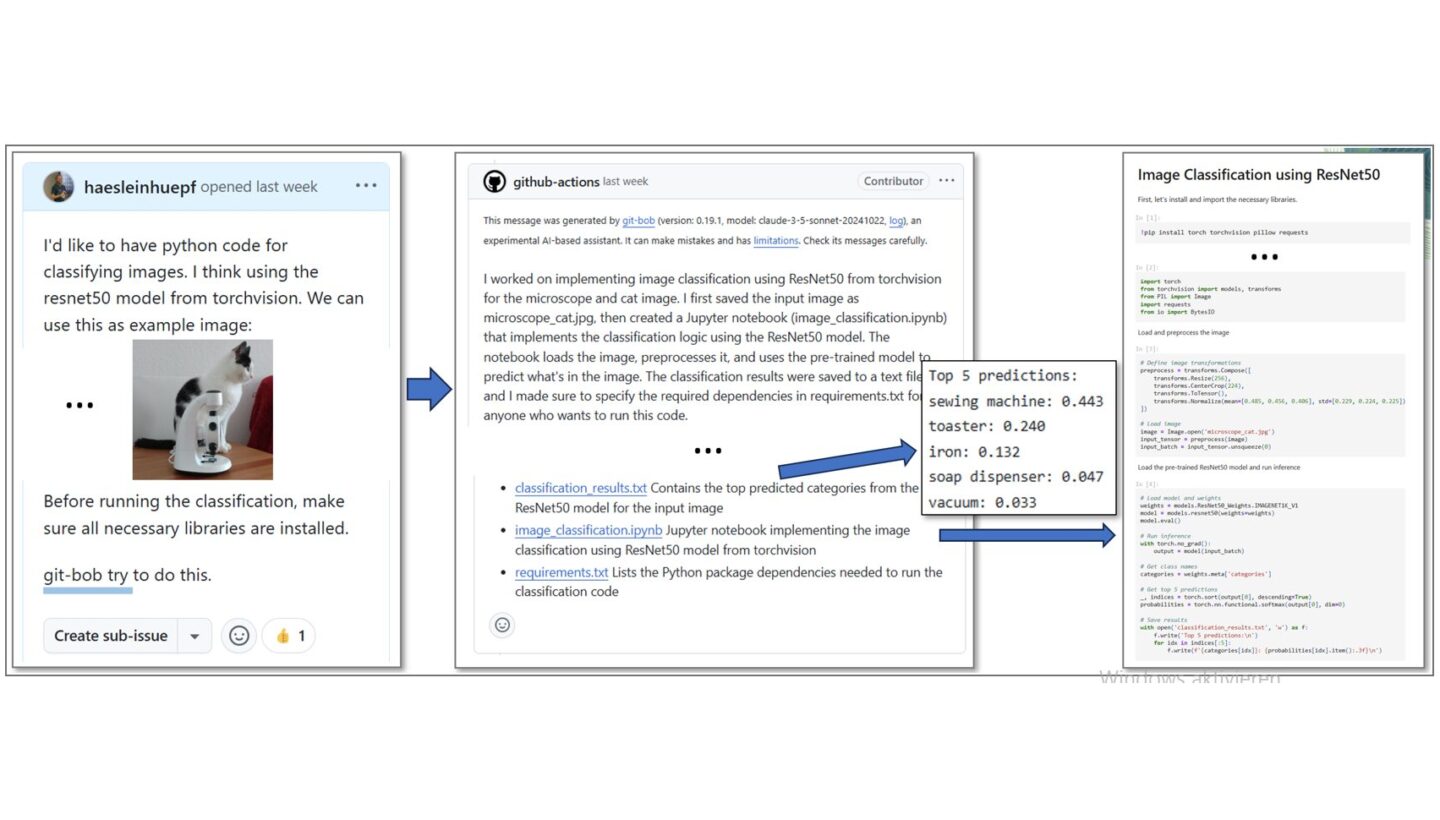
(Quelle: https://github.com/haesleinhuepf/git-bob-playground/issues/241)
Darüber hinaus funktioniert git-bob auch so niederschwellig wie möglich. Die Plattform nutzt die ohnehin meist ubiquitären Dienste Github und Gitlab und funktioniert somit online ohne Download und Installation. Zudem ist die Lösung Open-Source. Nutzer:innen können sie also auch auf eigenen Gitlab-Servern installieren, eigene Sprachmodell-Server einrichten und git-bob dann in vollkommen privater Umgebung nutzen.
Zurzeit orientiert sich die Nutzungsoberfläche von git-bob noch stark an den gewohnten Arbeitsumgebungen von Datenwissenschaftler:innen und Softwareentwickler:innen. Robert Haase plant nun die Plattform in einem nächsten Schritt auch für Bio- oder Geoforschung nutzbar zu machen.
Probieren Sie git-bob selbst
Die Publikation, in der git-bob vorgestellt wird, erscheint am 27. März in der Zeitschrift Nature Computational Science. Unter diesem Link finden Sie das Pre-Print Paper: https://zenodo.org/records/13928832
Wenn Sie sich für die Plattform und ihre Funktionen interessieren, können Sie sie hier ausprobieren: https://github.com/haesleinhuepf/git-bob



funded by:

ScaDS.AI Dresden/Leipzig (Zentrum für skalierbare Datenanalyse und Künstliche Intelligenz) ist ein Zentrum für Data Science, Künstliche Intelligenz und Big Data mit Standorten in Dresden und Leipzig.
Dresden
Besucheradresse
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postalische Adresse
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Besucheradresse
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postalische Adresse
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
