
18. März 2025
Junior Research Group CIAO macht Produktdesign menschenzentriert
ScaDS.AI Dresden/Leipzig
Seit Mai 2023 forschen unsere Nachwuchsforschungsgruppen an innovativen KI-Lösungen für Themen, die den Forschungshorizont unseres Zentrums erweitern. Von personalisierten Coaching-Programmen für Studierende über die Erforschung von Mobilität, die menschenzentriert und automatisiert ist, bis hin zu fortgeschrittenen Datenanalyseverfahren für ML-Systeme bringen die Nachwuchsgruppen neue Perspektiven in die Forschungswelt der KI und Data Science.
In dieser Podcast-Reihe stellen wir die einzelnen Gruppen und ihre Projekte vor. Dabei kommen die Forscherinnen und Forscher selbst zu Wort. Sie geben Einblicke in ihre Arbeit und berichten über die Zukunftsperspektiven ihrer Projekte. Alle Beiträge gibt es als Audio-Podcast (nur auf deutsch) und als Text (deutsch und englisch)
Unsere moderne Welt ist schlecht designt. Gut, das ist vielleicht ein wenig übertrieben. Aber in vielen Bereichen unseres Alltags treffen wir auf Systeme, Programme oder Interfaces, bei denen es sich so anfühlt, als wäre man selbst im Designprozess nicht mitgedacht worden:
- Schalter sind zu weit auseinander,
- Eingabefelder nicht intuitiv, oder
- es braucht sowieso viel zu lange, um von Einstellung A nach Funktion B zu kommen.
Produktentwicklung ist ein langwieriger und enorm kostenintensiver Prozess. Nutzungsstudien sind hier zwar essentiell, um Design und Funktion perfekt auf den Menschen abzustimmen. Häufig sind diese aber zu aufwendig und zu teuer, um sie im großen Maßstab durchzuführen; gerade für kleine Entwicklungsteams. Dadurch entsteht ein Problem.
Hanna Bussmann: Wahrscheinlich wird vor allem der Durchschnittsmensch getestet. Menschen, die diesem Durchschnitt nicht entsprechen, könnten ausgeschlossen werden oder das Gerät nicht oder nur eingeschränkt nutzen oder sogar ein erhöhtes Verletzungsrisiko eingehen.
Hannah Bussmann ist Studentin der Bioinformatik an der Uni Leipzig. Gerade schreibt sie an ihrer Masterarbeit bei ScaDS.AI, genauer in der Forschungsgruppe CIAO. Computational Interaction and Mobility, kurz CIAO, ist eine der Junior Research Groups von ScaDS.AI. Die Gruppe hat es sich zum Ziel gesetzt mithilfe von maschinellem Lernen Design- und Produktentwickungsprozesse menschenzentrierter zu gestalten. Geleitet wird sie von Dr. Patrick Ebel

Patrick Ebel: Wir bauen Nutzermodelle, also Computational Models, die letztendlich das Nutzerverhalten analysieren und vorhersagen können, um Interfaces zu verbessern. Diese Interfaces können zum einen das Smartphone Interface sein, also das UI, das man auf dem Smartphone hat, oder auch ein Infotainmentsystem im Auto.
Im Kern geht es darum menschliches Nutzungsverhalten bis ins Detail simulieren zu können. Wenn ein digitales System alle denkbaren und wahrscheinlichen Interaktionen eines Menschen mit einer Benutzeroberfläche simulieren kann, lassen sich Nutzungsstudien fast vollständig digitalisieren. Das beschleunigt nicht nur den Gestaltungsprozess und spart Kosten, sondern ermöglicht es auch kleinen Entwicklungsteams ihre Produkte im großen Stil zu testen, obwohl sie normalerweise keine Kapazität für umfassende Studien hätten.
Doch wie so oft ist das leichter gesagt als getan. Menschliches Verhalten ist äußerst vielschichtig und komplex – selbst bei scheinbar einfachen Aufgaben wie der Bedienung einer Smartphone-App.
In der Forschung verfolgt CIAO zwei Hauptansätze: datenbasierte Modellierung und Modellierung mittels Reinforcement Learning. Bei der datenbasierten Modellierung werden große Mengen von Nutzungsdaten verwendet, um dann mit Hilfe von maschinellem Lernen Muster zu erkennen.
Zwei Herangehensweisen: Datengesteuerte Modellierung…

Patrick Ebel: Die Modelle können einerseits datenbasiert sein, d.h. wenn Nutzungsdaten aufgezeichnet werden. Wo haben die Leute geklickt? Welche Apps haben sie geöffnet, welche Funktionen haben sie genutzt, wie lange haben sie dafür gebraucht?
Wenn man riesige Datenmengen hat, kann man sagen: Okay, gut, aus diesen Daten lernen wir das Interaktionsverhalten. Und dann gehen wir davon aus, dass, wenn die Datenmenge groß genug ist und wir eine bestimmte Metrik – zum Beispiel „Accuracy“ – nach unten drücken, wir ein Modell haben, das wirklich menschenähnlich interagiert.Das hat natürlich den Nachteil, dass wir erstens riesige Datenmengen zum Trainieren brauchen und zweitens das Verhalten des Modells nur bedingt erklärbar ist.
…und Reinforcement Learning
Der zweite Ansatz, Reinforcement Learning, funktioniert etwas anders. Die Idee ist hier, nicht mithilfe von existierenden Nutzungsdaten Verhalten zu antizipieren, sondern die Nutzenden selbst zu simulieren. Es geht also darum einen digitalen Agenten zu schaffen. Dieser versucht ohne vorheriges Wissen wie ein Mensch mit einem neuen Produkt umzugehen.
Die Grundlegende Theorie dahinter nennt sich Computational Rationality. Die Theorie der Computational Rationality beschreibt menschliches Verhalten als Ergebnis optimaler Entscheidungen unter begrenzten kognitiven und körperlichen Ressourcen.
Menschen sind nicht perfekt. Wir sind abgelenkt. Wir können kleine Schrift nur schwer lesen und unsere Reaktionsgeschwindigkeit reicht häufig gerade mal dafür dem zu Boden fallenden Sandwich hinterherzugucken, anstatt es zu fangen. Menschen haben nur begrenzte kognitive, motorische und sensorische Ressourcen. Um dennoch halbwegs erfolgreich agieren und leben zu können, muss sich der Mensch seiner Umwelt anpassen und effizient handeln.
Digitale Systeme funktionieren grundlegend anders. Diese sind meist darauf ausgelegt, Aufgaben möglichst schnell und genau zu erledigen. Limitationen wie selektive Wahrnehmung oder Ablenkung kennt ein Computer nicht. Soll jedoch menschliches Verhalten simuliert werden, muss der digitale Agent seine Aufgaben somit nicht perfekt, sondern möglichst menschenähnlich ausführen: also langsamer und fehlerhaft. Dazu werden ihm künstliche Grenzen gesetzt.

Patrick Ebel: Wir wollen Agenten entwickeln, denen wir gezielt „Boundaries“ auferlegen. Wenn ein Reinforcement-Learning-Agent eine Aufgabe bekommt, verhält er sich oft übermenschlich. Unsere Idee ist es jedoch nicht, ein solches übermenschliches Verhalten zu erzeugen, sondern ein möglichst menschenähnliches.
Ein einfaches Beispiel wäre ein Agent, der Auto fahren soll. Ein klassischer technischer Agent würde mit einer Kamera arbeiten, die das gesamte Sichtfeld gleichzeitig scharf abbildet und genau weiß, wo sich jedes Objekt befindet. Menschen hingegen sehen nur einen kleinen Bereich scharf und müssen ihre Umgebung aktiv erkunden.
Deshalb geben wir dem Reinforcement-Learning-Agenten ein Augenmodell mit, so dass er seine Umgebung nur so wahrnehmen kann, wie es ein Mensch tun würde. Dabei orientieren wir uns stark an Erkenntnissen aus der Kognitions- und Experimentalpsychologie – etwa wie lange ein Mensch braucht, um von einem Punkt zum anderen zu blicken. Durch diese „Boundaries“ und eine gezielte Optimierung der Aufgaben wollen wir ein möglichst realistisches menschliches Verhalten abbilden.
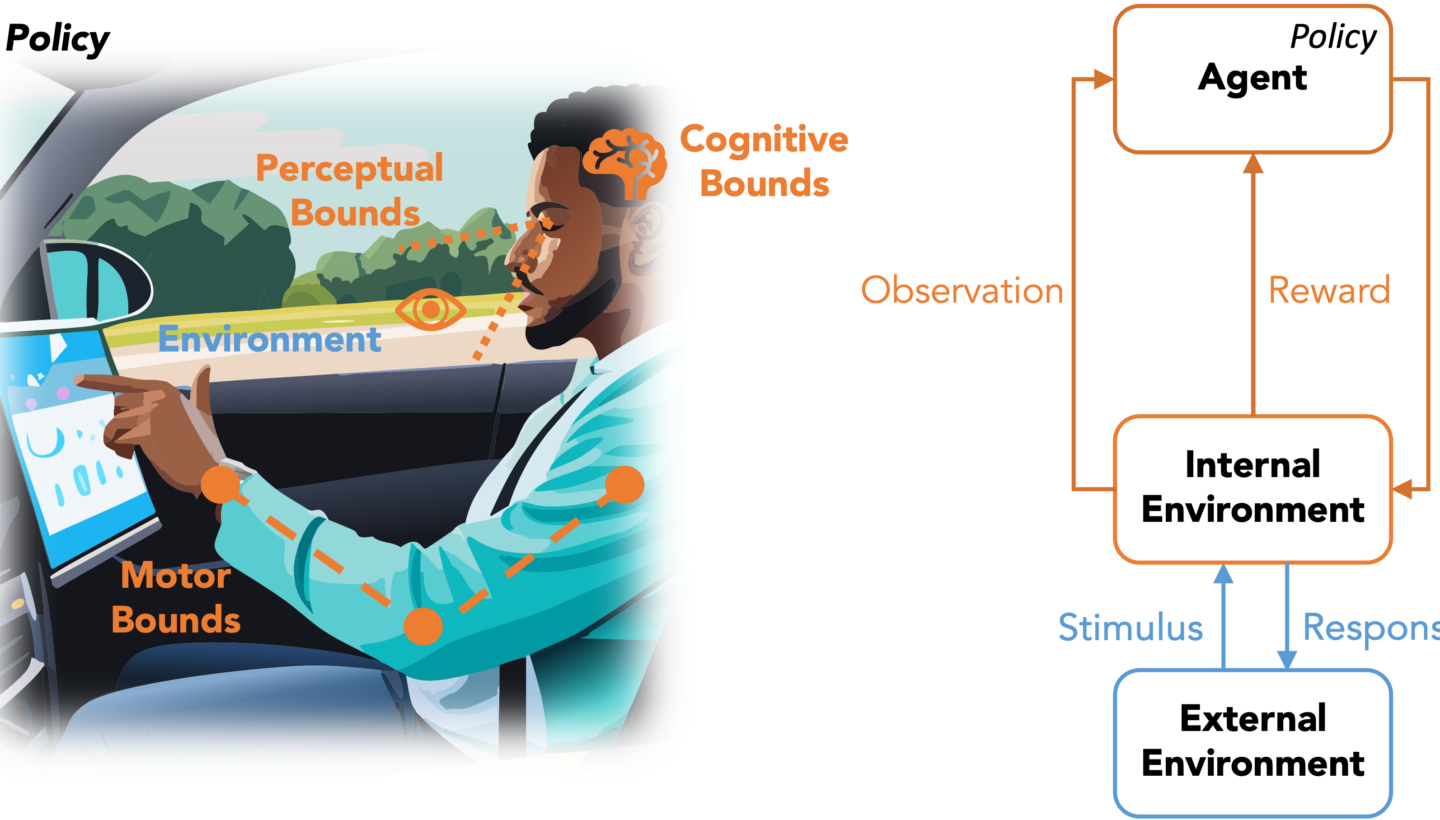
Computational Rationality und Boundaries
Bei der Entwicklung der Reinforcement Learning Agenten orientiert sich die Forschungsgruppe an Wissen aus der Kognitions- und Experimentalpsychologie, wie auch an der Biomechanik. Will man eine simple Handbewegung, wie das Tippen auf einem Bildschirm simulieren braucht es dafür mindestens drei Dinge.
- Wahrnehmung. Wichtige Fragen sind hier beispielsweise, wie schnell wir unsere Aufmerksamkeit auf einen neuen Reiz ausrichten können oder wie klein Symbole und Text sein dürfen, damit wir sie erkennen.
- Kognition, also beispielsweise wie viele Reize wir gleichzeitig verarbeiten können, wie viel sich unser Kurzzeitgedächtnis merken kann und wie schnell wir reagieren können.
- Motorik: Wie schnell bewegen wir unseren Arm? Wie lang und präzise sind unsere Finger, wie beweglich unser Handgelenk?
Sind in einem System alle drei Aspekte modelliert, kann anhand von Daten aus kognitionspsychologischen Experimenten langsam ein digital simulierter Mensch, ein sogenannter Digital Twin, konstruiert werden. Sind alle wichtigen Aspekte des Digital Twin modelliert, lässt er sich über die „Boundaries“, also die menschlichen Grenzen, relativ einfach anpassen und individualisieren. Auf diese Weise kann nicht nur der Durchschnitt simuliert werden, sondern ein breites Spektrum unterschiedlicher Menschen.
Hanna Bussmann: Ich kann die Finger verlängern, die Handfläche vergrößern oder Einschränkungen wie Muskelerkrankungen oder -schwächen modellieren. Anschließend kann ich überprüfen, wie gut die Usability eines Interfaces für Menschen mit unterschiedlichen Attributen ist.
Patrick Ebel: Wenn ich die Ergonomie eines Smartphones evaluieren möchte und dazu zehn Personen einlade, dann sind wahrscheinlich alle in einem bestimmten Größenbereich. Es ist eher unwahrscheinlich, dass jemand dabei ist, der nur 1,51 Meter oder 2,10 Meter groß ist.
Genau hier werden Reinforcement-Learning-Modelle interessant, weil wir in diesem Fall keine realen Nutzungsdaten benötigen. Stattdessen können wir unsere Modelle und deren „Boundaries“, wie zum Beispiel die Handgröße, gezielt anpassen und beobachten, wie sich die Interaktion dadurch verändert. Gerade dafür sind Computational Rational Models besonders spannend.
Die Vorteile von Reinforcement Learning
Ist eine App oder ein Fahrassistenzsystem überhaupt gut nutzbar für Menschen mit kleineren Händen oder etwas schlechteren Augen? Reeinforcement Learning Modelle können es herausfinden. Da der Ansatz nicht auf bereits existierende Daten angewiesen ist, können verschiedene simulierte Einschränkungen einfach ausprobiert werden. Darüber hinaus sind Reinforcement Learning Modelle auch sehr flexibel einsetzbar.
Patrick Ebel: Wenn wir beispielsweise Daten von Benutzern sammeln, die mit iOS interagieren, stellt sich die Frage, ob diese Daten für die Evaluation von Android-Systemen verallgemeinert werden können – wahrscheinlich nicht. Wenn wir jedoch ein Computational Framework verwenden, kann der Agent lernen, Schnittstellen generell wahrzunehmen und mit ihnen zu interagieren. Das heißt, er kann sowohl auf Android als auch auf iOS trainiert und dann zur Evaluation eingesetzt werden.
Im Idealfall müsste man dann nicht mehr ständig Expertinnen und Experten hinzuziehen, sondern hätte ein Modell, das direkt in Design-Tools wie Figma integriert ist. Es könnte in Echtzeit Feedback geben, zum Beispiel: „Der Like-Button ist etwas klein geraten, vergrößere ihn lieber“ oder „Verwende hier dezentere Farben, damit das Design als ästhetischer wahrgenommen wird“.

Bis CIAO allerdings so weit ist, wird es noch Zeit brauchen. Ein menschliches Reiz-Reaktionssystem von Grund auf zu modellieren, benötigt nicht nur viel Rechenleistung sondern auch sehr aufwendige Detailarbeit. Hannah Bussmanns Masterarbeit untersucht beispielsweise, wie sich die Biomechanik I von Tastaturtippen simulieren lässt. In ihrem Modell muss sie über 60 verschiedene Muskeln, mit unterschiedlichen Stärken und Reichweiten beachten und das nur um einen Finger über eine Tastatur zu bewegen. Situationen wie Autofahren sind dann nochmal komplexer.
Patrick Ebel: Natürlich gibt es noch Herausforderungen, wie zum Beispiel, dass die Vorhersagegenauigkeit noch lange nicht auf dem gewünschten Niveau ist oder dass eine große Menge an Trainingsdaten benötigt wird. Außerdem verhalten sich Reinforcement-Learning-Agenten oft unvorhersehbar oder reagieren empfindlich auf Veränderungen. Es gibt also noch viel zu tun.
Chances and Current Research

Ursprünglich konzentrierte sich die Arbeit der Forschungsgruppe auf die Verbesserung von Mobilität und Nutzunhsschnittstellen in Fahrzeugen. Inzwischen wird die Grundidee, menschliches Verhalten zu simulieren, von der Gruppe in verschiedenen Bereichen bearbeitet mit insgesamt 3 Doktorarbeiten, 2 Masterarbeiten und diversen weiteren internen Projekten.
Zu den aktuellen Forschungen gehören im Bereich Reinforcement Learning die biomechanische Modellierung des menschlichen Arms, die Modellierung des Situationsbewusstseins sowie eine Modellierung für Videospiele auf einer alten Atari-Konsole. Hinzu kommen datenbasierte Projekte wie die Analyse von Infotainmentsystemen im Auto oder die Entwicklung eines generativen Agenten, der den Verkehr einer ganzen Stadt simulieren kann. Darüber hinaus arbeitet die Forschungsgruppe an einem VR-unterstützten Fahrsimulator, mit dem Experimente zur Optimierung des „Digital Twin“ durchgeführt werden.
Das Feld, in dem CIAO, Patrick Ebel und Hanna Bussmann arbeiten, ist riesig und das Potenzial enorm. Bei der Frage, wie wir unsere digitalisierte Gesellschaft mit all ihren Bildschirmen und Nutzungsoberflächen optimieren können, geht es nicht nur um Komfort, sondern auch um Zugänglichkeit, Effizienz und Sicherheit.
Menschliches Verhalten zu verstehen und in digitale Modelle zu übersetzen bleibt eine Herausforderung – aber die Forschung der Junior Research Group zeigt, dass menschzentriertes Design mit maschinellem Lernen nicht nur möglich ist, sondern richtungsweisend für eine besser designte Zukunft.


funded by:

ScaDS.AI Dresden/Leipzig (Zentrum für skalierbare Datenanalyse und Künstliche Intelligenz) ist ein Zentrum für Data Science, Künstliche Intelligenz und Big Data mit Standorten in Dresden und Leipzig.
Dresden
Besucheradresse
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postalische Adresse
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Besucheradresse
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25,
3. Obergeschoss
04105 Leipzig
Löhrs Carré
Humboldtstraße 25,
3. Obergeschoss
04105 Leipzig
Postalische Adresse
Universität Leipzig
Data Science Zentrum
Internes Postfach: 212104
04081 Leipzig
Data Science Zentrum
Internes Postfach: 212104
04081 Leipzig
Quicklinks:
Copyright 2025 © SCADS.AI Dresden/Leipzig – All rights reserved.
