
August 5, 2025
ACL 2025 in Vienna, Austria
Research
From July 27 to August 1 the 63rd Annual Meeting of the Association for Computational Linguistics ACL 2025 took place in Vienna, Austria. As one of the most important high-profile conferences for research in the field of natural language processing the ACL conference changes its venue every year, selecting locations with a significant computational linguistics research background.
Contributions to ACL 2025 by ScaDS.AI Dresden/Leipzig
ScaDS.AI Dresden/Leipzig reseachers joined over 3000 other researchers attending on site and virtually this year and presented their work. The following contributions from our center enriched the conference program:
Authors: Yujia Hu, Tuan-Phong Nguyen, Shrestha Ghosh, Simon Razniewski (Main conference paper)
Link to the paper.
Abstract: Large language models (LLMs) have majorly advanced NLP and AI, and next to their ability to perform a wide range of procedural tasks, a major success factor is their internalized factual knowledge. Since Petroni et al. (2019), analyzing this knowledge has gained attention. However, most approaches investigate one question at a time via modest-sized pre-defined samples, introducing an “availability bias” (Tversky and Kahneman, 1973) that prevents the analysis of knowledge (or beliefs) of LLMs beyond the experimenter’s predisposition. To address this challenge, we propose a novel methodology to comprehensively materialize an LLM’s factual knowledge through recursive querying and result consolidation. Our approach is a milestone for LLM research, for the first time providing constructive insights into the scope and structure of LLM knowledge (or beliefs). As a prototype, we build GPTKB, a knowledge base (KB) comprising 101 million relational triples for over 2.9 million entities from GPT-4o-mini. We use GPTKB to exemplarily analyze GPT-4o-mini’s factual knowledge in terms of scale, accuracy, bias, cutoff and consistency, at the same time. GPTKB is accessible at https://gptkb.org.
Authors: Valentin Knappich, Anna Hätty, Simon Razniewski, Annemarie Friedrich (Findings papers)
Link to the paper
Abstract: Dealing with long and highly complex technical text is a challenge for Large Language Models (LLMs), which still have to unfold their potential in supporting expensive and time-intensive processes like patent drafting. Within patents, the description constitutes more than 90% of the document on average. Yet, its automatic generation remains understudied. When drafting patent applications, patent attorneys typically receive invention reports (IRs), which are usually confidential, hindering research on
LLM-supported patent drafting. Often, prepublication research papers serve as IRs. We leverage this duality to build PAP2PAT, an open and realistic benchmark for patent drafting consisting of 1.8k patent-paper pairs describing the same inventions. To address the complex long-document patent generation task, we propose chunk-based outline-guided generation using the research paper as technical specifi-
cation of the invention. Our extensive evaluation using PAP2PAT and a human case study show that LLMs can effectively leverage information from the paper, but still struggle to provide the necessary level of detail. Fine-tuning leads to more patent-style language, but also to more hallucination. We release our data and code at https://github.com/boschresearch/Pap2Pat.
Authors: Tim Schopf, Juraj Vladika, Michael Färber, and Florian Matthes
Link to the paper
Abstract: Modern generative Large Language Models (LLMs) are capable of generating text that sounds coherent and convincing, but are also prone to producing hallucinations, facts that contradict the world knowledge. Even in the case of Retrieval-Augmented Generation (RAG) systems, where relevant context is first retrieved and passed in the input, the generated facts can contradict or not be verifiable by the provided references. This has motivated SciHal 2025, a shared task that focuses on the detection of hallucinations for scientific content. The two sub-tasks focused on: (1) predicting whether a claim from a generated LLM answer is entailed, contradicted, or unverifiable by the used references; (2) predicting a fine-grained category of erroneous claims. Our best performing approach used an ensemble of fine-tuned encoder-only ModernBERT and DeBERTa-v3 models for classification. Out of nine competing teams, our approach achieved the first place in sub-task 1 and the second place in sub-task 2.
Authors: Nicholas Popovič, Ashish Kangen, Tim Schopf, Michael Färber
Link to the paper
Abstract: Large, high-quality annotated corpora remain scarce in document-level entity and relation extraction in zero-shot or few-shot settings. In this paper, we present a fully automatic, LLM-based pipeline for synthetic data generation and in-context learning for document-level entity and relation extraction. In contrast to existing approaches that rely on manually annotated demonstrations or direct zero-shot inference, our method combines synthetic data generation with retrieval-based in-context learning, using a reasoning-optimized language model. This allows us to build a high-quality demonstration database without manual annotation and to dynamically retrieve relevant examples at inference time. Based on our approach we produce a synthetic dataset of over 5k Wikipedia abstracts with approximately 59k entities and 30k relation triples. Finally, we evaluate in-context learning performance on the DocIE shared task, extracting entities and relations from long documents in a zero-shot setting. We find that in-context joint entity and relation extraction at document-level remains a challenging task, even for state-of-the-art large language models.
Impressions from the conference
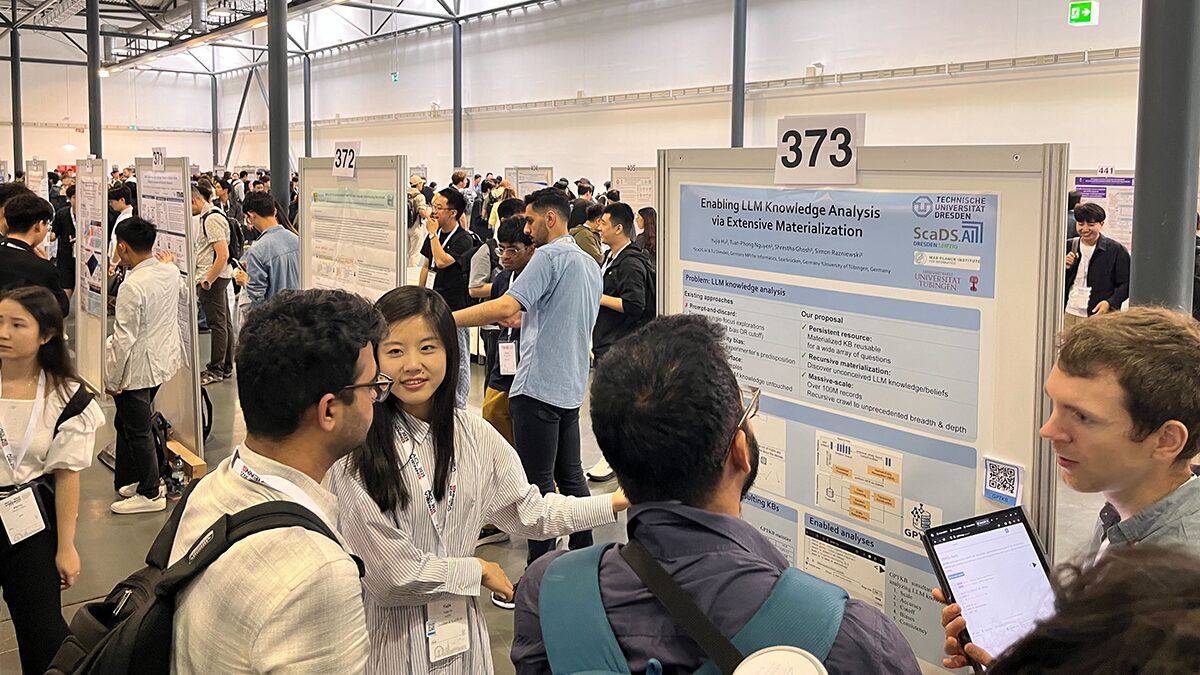
One of the main conference papers was “Enabling LLM Knowledge Analysis via Extensive Materialization” by Yujia Hu (ScaDS.AI Dresden/Leipzig), Tuan-Phong Nguyen (Max Planck Institute for Informatics, Saarbrücken), Shrestha Ghosh (University of Tübingen)and Simon Razniewski (ScaDS.AI Dresden/Leipzig). Yujia Hu and Simon Raznieski presented it on different days of the conference. This led to great discussions and they received valuable feedback on their work. They also took the opportunity to meet up with old and new colleagues from other AI centers and research institutions.
The paper “Natural Language Inference Fine-tuning for Scientific Hallucination Detection” by Tim Schopf (ScaDS.AI Dresden/Leipzig), Juraj Vladika (Technical University of Munich), Michael Färber (ScaDS.AI Dresden/Leipzig) and Florian Matthes (Technical University of Munich) investigated approaches to detect hallucinations (i.e. inaccurate claims) in LLM-generated scientific responses. In particular, they detected hallucinations in real-world GenAI search engines. Those were used to generate answers to science questions and grounded in scientific documents. Their hallucination detection approach successfully identified these inaccuracies. It topped the leaderboard at the SciHal25 Shared Task, winning 1st place overall! The shared task was part of the fifth iteration of the workshop on Scholarly Document Processing within the ACL 2025.
“In-Context Learning for Information Extraction using Fully Synthetic Demonstrations” by Nicholas Popovič, Ashish Kangen, Tim Schopf, Michael Färber was presented as part of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM). The authors investigated the use of state-of-the-art reasoning LLMs as data annotators for information extraction. This is a task where the goal is to turn texts into knowledge graphs. They created a high quality dataset that is now available for future research. Furthermore they reported several insights about challenges of using LLMs for this task and how they overcame these in their work.






funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
