November 11, 2025
ScaDS.AI Dresden/Leipzig at EMNLP 2025
Research
From November 4–9, 2025, Prof. Michael Färber, Shuzhou Yuan and Nicholas Popovič joined the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025) in Suzhou, China. With around 4,000 participants this year, EMNLP 2025 is one of the largest NLP conferences worldwide.
Contributed papers
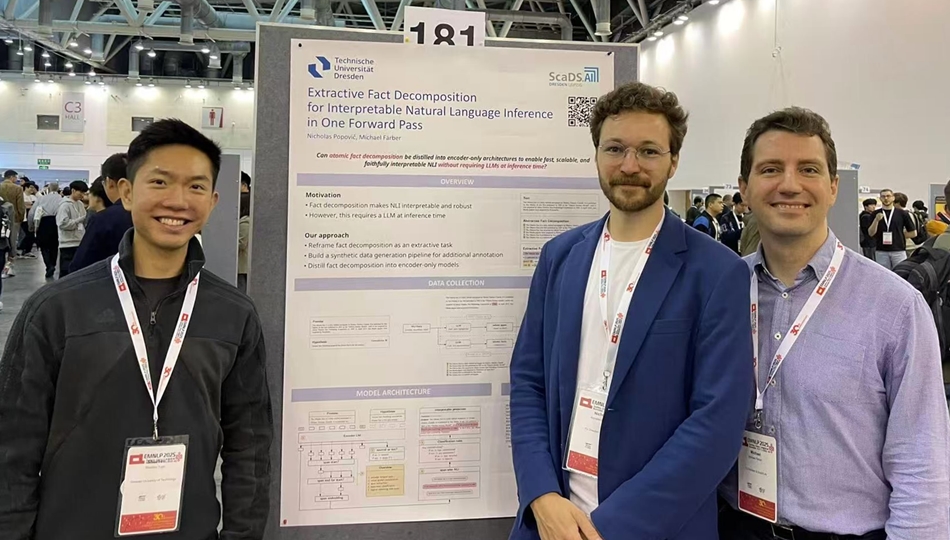
Extractive Fact Decomposition for Interpretable Natural Language Inference in One Forward Pass
Recent works in Natural Language Inference (NLI) and related tasks, such as automated fact-checking, employ atomic fact decomposition to enhance interpretability and robustness. For this, existing methods rely on resource-intensive generative large language models (LLMs) to perform decomposition. In this paper, Nicholas Popovič and Michael Färber propose JEDI, an encoder-only architecture that jointly performs extractive atomic fact decomposition and interpretable inference without requiring generative models during inference. To facilitate training, they produce a large corpus of synthetic rationales covering multiple NLI benchmarks. Experimental results demonstrate that JEDI achieves competitive accuracy in distribution and significantly improves robustness out of distribution and in adversarial settings over models based solely on extractive rationale supervision. Their findings show that interpretability and robust generalization in NLI can be realized using encoder-only architectures and synthetic rationales.
Graph-Guided Textual Explanation Generation Framework
Natural language explanations (NLEs) are commonly used to provide plausible free-text explanations of a model’s reasoning about its predictions. However, recent work has questioned their faithfulness, as they may not accurately reflect the model’s internal reasoning process regarding its predicted answer. In contrast, highlight explanations–input fragments critical for the model’s predicted answers–exhibit measurable faithfulness.
Building on this foundation, the authors propose G-TEx, a Graph-Guided Textual Explanation Generation framework designed to enhance the faithfulness of NLEs. Specifically, highlight
explanations are first extracted as faithful cues reflecting the model’s reasoning logic toward answer prediction. They are subsequently encoded through a graph neural network layer to guide the NLE generation, which aligns the generated explanations with the model’s underlying reasoning toward the predicted answer. Experiments on both encoder-decoder and decoder-only models across three reasoning datasets demonstrate that G-TEx improves NLE faithfulness by up to 12.18% compared to baseline methods. Additionally, G-TEx generates NLEs with greater semantic and lexical similarity to human-written ones. Human evaluations show that G-TEx can decrease redundant content and enhance the overall quality of NLEs. Their work presents a novel method for explicitly guiding NLE generation to enhance faithfulness, serving as a foundation for addressing broader criteria in NLE and generated text.
This paper is authored by Shuzhou Yuan, Jingyi Sun, Ran Zhang, Michael Färber, Steffen Eger, Pepa Atanasova, and Isabelle Augenstein. Read it here.
COMPLEXTEMPQA: A 100 m Dataset for Complex Temporal Question Answering
Raphael Gruber, Abdelrahman Abdallah, Michael Färber, and Adam Jatowt introduce COMPLEXTEMPQA,1 a largescale dataset consisting of over 100 million question-answer pairs designed to tackle the challenges in temporal question answering. COMPLEXTEMPQA significantly surpasses existing benchmarks in scale and scope. Utilizing Wikipedia and Wikidata, the dataset covers questions spanning over two decades and offers an unmatched scale. We introduce a new taxonomy that categorizes questions as attributes, comparisons, and counting questions, revolving around events, entities, and
time periods, respectively. A standout feature of COMPLEXTEMPQA is the high complexity of its questions, which demand reasoning capabilities for answering such as across-time comparison, temporal aggregation, and multihop reasoning involving temporal event ordering and entity recognition. Additionally, each question is accompanied by detailed metadata, including specific time scopes, allowing for comprehensive evaluation of temporal reasoning abilities of large language models.
Hateful Person or Hateful Model? Investigating the Role of Personas in Hate Speech Detection by Large Language Models
Hate speech detection is a socially sensitive and inherently subjective task, with judgments often varying based on personal traits. While prior work has examined how sociodemographic factors influence annotation, the impact of personality traits on Large Language Models (LLMs) remains largely unexplored. In this paper, we present the first comprehensive study on the role of persona prompts in hate speech classification, focusing on MBTI-based traits. A human annotation survey confirms that MBTI dimensions significantly affect labeling behavior. Extending this to LLMs, we prompt four open-source models with MBTI personas and evaluate their outputs across three hate speech datasets. Our analysis uncovers substantial persona-driven variation, including inconsistencies with ground truth, inter-persona dis-
agreement, and logit-level biases. These findings highlight the need to carefully define persona prompts in LLM-based annotation workflows, with implications for fairness and alignment with human values
The authors of this paper are huzhou Yuan, Ercong Nie, Mario Tawfelis, Helmut Schmid, Hinrich Schütze, and Michael Färber. It was presented at the PALS NLP Workshop @ EMNLP 2025. The full text is available here.


funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
