Knowledge
Knowledge Aware Computing (Prof. Krötzsch)
We want to enable a tighter integration of knowledge-driven and statistical approaches to AI by laying the foundations for a knowledge-aware computing architecture. Therefore we are going to design an initial rule-based language for expressive recursive view definitions over knowledge graphs and investigate the conceptual foundations of integrating other AI methods in this rule-based framework based on well-defined interfaces. Furthermore, we develop methods for interpreting and validating results of other AI formalisms with respect to the original knowledge graph and create a prototype implementation of these concepts, and evaluate it for performance and utility.
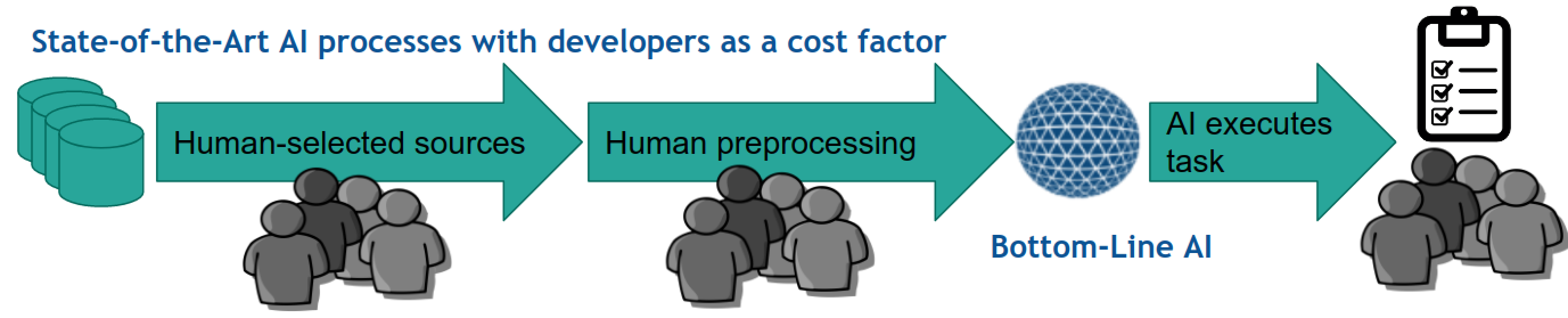
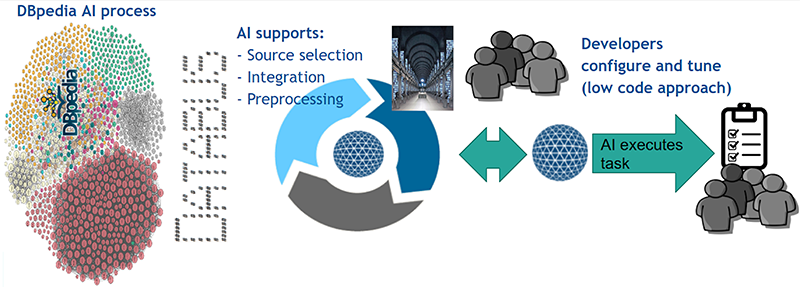
Knowledge Graphs for AI (Dr. Hellmann, Prof. Rahm)
We strive for an AI-based maintenance and generation of the largest free and open knowledge graph (LOD). This will allow the export and usage of millions of derived knowledge graphs for individual AI use cases.
Conversational AI: Combining Deep Learning and Large-Scale Knowledge Graphs (Prof. Lehmann)
The project investigates on hybrid AI approaches for integrating data as background knowledge into a dialogue system and on end-to-end learning approaches trained on raw dialogue data. This will help to build solutions which support users control systems that were previously reserved for experts, such as robots or data science tool chains. This also includes the development of verbalization strategies to ensure a natural formulation of answers.
Web Mining and Crowdsourcing for Scalable Training Data Acquisition (Jun.-Prof. Potthast)
This project studies the acquisition of training data from the web for distant supervision, which involves three aspects:
- The Web as Corpus
- Almost all aspects of society are represented on the web. Many prediction tasks relate to supporting humans.
- The web is harnessed to fuel machine learning models.
- Distant supervision
- For a given task, one does not necessarily need data that ideally matches the problem.
- Rather, one can get by with loosely matching data.
- Key goal is the semi-automatic search for such data.
- Crowd-sourcing
- Many tasks require the additional labeling of data.
- Scale can only be attained by outsourcing to the crowd.
- Key goal is the facilitation of crowd-sourcing by dedicated tools, and the automation of designing worker interfaces.

Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
