
System and Compiler Design for Emerging CNM/CIM Architectures
Title: System and Compiler Design for Emerging CNM/CIM Architectures
Duration: 08/2022 – today
Research Area: Architectures / Scalability / Security
Machine learning and data analytics applications increasingly suffer from the high latency and energy consumption of conventional von Neumann architectures. Computing-near-memory (CNM) and computing-in-memory (CIM) represent a paradigm shift in computing efficiency. Unlike traditional systems, where processing units and main memory are loosely connected by buses, leading to energy-intensive data movement, CNM/CIM systems enable computations close to where the data resides. Over the past decade, research in this area has surged, driven by the escalating demands of modern applications, as clearly seen in the increasing data and processing volume required by ML-based solutions. Although CNM/CIM systems deliver unprecedented performance and energy efficiency in the AI domain, they are only accessible to hardware experts, preventing broader adoption.
Aims
Our goal is to enable portability of AI and Big Data applications across existing CNM/CIM systems and novel accelerator designs, prioritizing performance, accuracy, and energy efficiency.
Problem
Despite advancements in emerging memory and integration technologies, current programming models are often technology-specific and low-level. Given the substantial differences compared to conventional machines, new compiler abstractions and frameworks are crucial to fully exploit the potential of CIM by providing automatic device-aware and device-agnostic optimizations and facilitate widespread adoption.
Practical example
We have developed reusable abstractions and showcased compilation flows tailored for CIM systems with memristive crossbar arrays (MCAs), content-addressable memories (CAMs), CIM-logic modules, and for CNM systems like UPMEM. Additional information about them can be found in the referenced publications below.
Technology
Our MLIR-based compiler can abstract computational primitives of memory devices, and their programming models and optimize data flow while considering hardware non-idealities. As input, this flow takes codes written in high-level (domain-specific) languages such as C, PyTorch and TensorFlow.

The hierarchal flow enables device-agnostic/aware analyses and transformations, allowing us to map computational patterns, like dot-products and similarity search, to the most suitable hardware target, such as CAMs and MCAs.
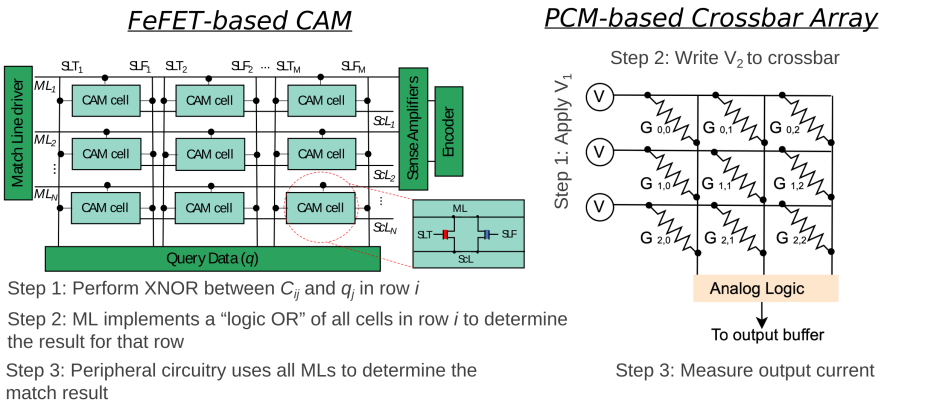
Outlook
The versatility of CNM/CIM systems has proven attractive for a wide range of applications, especially deep learning tasks like inference and training, benefiting from orders of magnitude improvement in performance and energy efficiency. Nonetheless, advancing automation, especially in heterogeneous systems, requires further cross-layer collaboration and development to enable the mapping of more complex ML models.
Publications
- Asif Ali Khan, João Paulo C. de Lima, Hamid Farzaneh, Jeronimo Castrillon, “The Landscape of Compute-near-memory and Compute-in-memory: A Research and Commercial Overview”, arXiv preprint arXiv:2401.14428, Jan 2024.
- Julien Ryckaert, Michael Niemier, Zephan Enciso, Mohammad Mehdi Sharifi, X. Sharon Hu, Ian O’Connor, Alexander Graening, Ravit Sharma, Puneet Gupta, Jeronimo Castrillon, João Paulo C. de Lima, Asif Ali Khan, Hamid Farzaneh, “Smoothing Disruption Across the Stack: Tales of Memory, Heterogeneity, and Compilers”, (to appear), Proceedings of the 2024 Design, Automation and Test in Europe Conference (DATE), IEEE, pp. 1-6, Mar 2024.
- Hamid Farzaneh, João Paulo C. de Lima, Mengyuan Li, Asif Ali Khan, Xiaobo Sharon Hu, Jeronimo Castrillon, “C4CAM: A Compiler for CAM-based In-memory Accelerators”, arXiv preprint arXiv:2309.06418, Sep 2023.
- Jörg Henkel, Lokesh Siddhu, Lars Bauer, Jürgen Teich, Stefan Wildermann, Mehdi Tahoori, Mahta Mayahinia, Jeronimo Castrillon, Asif Ali Khan, Hamid Farzaneh, João Paulo C. de Lima, Jian-Jia Chen, Christian Hakert, Kuan-Hsun Chen, Chia-Lin Yang, Hsiang-Yun Cheng, “Special Session – Non-Volatile Memories: Challenges and Opportunities for Embedded System Architectures with Focus on Machine Learning Applications”, Proceedings of the 2023 International Conference on Compilers, Architecture, and Synthesis of Embedded Systems (CASES), pp. 11–20, Sep 2023.
- João Paulo C. de Lima, Asif Ali Khan, Hamid Farzaneh, Jeronimo Castrillon, “Efficient Associative Processing with RTM-TCAMs”, In Proceeding: 1st in-Memory Architectures and Computing Applications Workshop (iMACAW), co-located with the 60th Design Automation Conference (DAC’23), 2pp, Jul 2023.
- Asif Ali Khan, Hamid Farzaneh, Karl F. A. Friebel, Clément Fournier, Lorenzo Chelini, Jeronimo Castrillon, “CINM (Cinnamon): A Compilation Infrastructure for Heterogeneous Compute In-Memory and Compute Near-Memory Paradigms”, arXiv preprint arXiv:2301.07486, Jan 2023.
Team
Lead
- Prof. Dr. Jeronimo Castrillon
Team Members
- Joao Paulo C. de Lima
- Asif Ali Khan
- Hamid Farzaneh
Partners
- Mahta Mayahinia, Mehdi B. Tahoori (Karlsruher Institut für Technologie, DE),
- Mengyuan Li, Xiaobo S. Hu (University of Notre Dame, US)
- Alex K. Jones (University of Pittsburg, US)

Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
