
February 21, 2017
Big Data frameworks on highly efficient computing infrastructures
Transfer and Service
Big Data is usually used as a synonym for Data Science on huge datasets. It is also dealing with all kinds of obstacles coming with that. Having access to a large amount of data offers a high potential to find more accurate results for many questions. Moreover, the ability to handle Big Data volumes may facilitate solutions to previously unsolved problems. However, many research groups have not the necessary facilities to run large analysis jobs using computing resources they have access to at their home institution. Furthermore, the installation, administration and maintenance of a complex and agile software stack for data analytics is often a challenging task for domain scientists.
One of the key issues of the Big Data competence center ScaDS Dresden/Leipzig is therefore to provide multi-purpose data analytics frameworks for research communities, which can be used directly at the computing resources of the Center for Information Services and High Performance Computing (ZIH). We are using the high performance computing (HPC) infrastructure of ZIH. Therefore, our team members and collaborating researchers can run their data analytics pipelines massively in parallel on modern hardware. The following general purpose data analytics frameworks are currently available:
This list is not fixed, since other software projects will be provided upon request. Because Deep-Learning is often related to Big Data, the ZIH currently also evaluates Deep-Learning frameworks. Those might be used for optimization problems.
Comparison to Shared-Nothing Systems
The provisioning of Big Data frameworks on HPC infrastructure is slightly different compared to typically used Shared-Nothing architectures. Usually, the frameworks assume to run exclusively on a given number of nodes in their own environments. In contrast to that, we provide these frameworks for HPC machines. Those HPC machines are used by a large research community, sharing the same computing and storage resources. In this environment, HPC users often use highly optimized programs for simulations or models. Traditionally, they do not use Big Data frameworks in the first place. However, Big Data frameworks have developed in parallel to paradigms traditionally used in the HPC community. Those Big Data frameworks tend to become important for researchers these days.
The advantages are a highly dynamic development community and libraries and projects. With that, Big Data frameworks steadily enhance the data analytics software stack with advanced analytical methods. The frameworks also provide means to distribute workloads in a data-driven way over the available cluster. In this way, users, which might not be familiar with HPC in general, get the possibility to express their workflow with easy-to-learn parallel computing paradigms. This is required because researchers need to apply their algorithms to the increasing volume of their data. Concepts of Big Data frameworks can help to simplify the implementation works required to set up an analysis pipeline for large data setts.
Benefits of using Big Data frameworks in the ZIH data centers:
- Homogeneous resources are used, i.e. CPU resources and storage.
- Many computing and storage resources can be used.
- Various configurations of cluster and application setups can be tested.
- For test or benchmark runs, the configuration can be saved automatically.
- Existing workflows can be moved easily to high performance computers.
- Existing high performance computing workflows can be extended by analytics.
- Users have their own environment and don’t share computing resources or data with others (separate instances of the frameworks).
The HPC environment at ZIH
Compared to a bigger bunch of storage available attached locally to each computing node in shared-nothing clusters, HPC nodes have usually less local storage available. For higher storage demands, a LUSTRE filesystem is available. It offers a high bandwidth and high IOPs rate to computing nodes. However, using a LUSTRE-based file system, running a Hadoop distributed file system (HDFS) instance is not necessary for storing data in parallel. Also on the storage level, we provide different LUSTRE file systems for varying purposes (HDD- and SDD-based). In the future, the ZIH plans to provide more flexible solutions by providing configurations with more local storage available.
In addition to our fast storage infrastructure, the widely used SLURM scheduler is used as a resource negotiator. Furthermore, it can be used as a job manager in the HPC environment. Beside the this standard setting, we plan to support in future special usage scenarios by extending the job scheduling mechanism to also provide subsets of the available nodes accessible exclusively to groups of researchers for a longer period of time, which then can run their specialized infrastructure in this environment exclusively.
Cluster setup in HPC environment
In the following a description is given to illustrate the differences between the current HPC machine’s environment with its job scheduling system and the usual way using a Shared-Nothing cluster.
To explain the steps needed to create a cluster dynamically, we first collect a few requirements. Users should be able to work in parallel, that means it should be possible to have multiple instances of a framework running. This is not only necessary to let many users work on their own cluster setup, but also to let them have an arbitrary number of clusters. Clusters should start when the user demands it. It should be relatively easy to use another configuration, e.g. more HPC nodes for scaling tests or simply run analysis pipelines with more data at hand. This means that clusters are created dynamically, each potentially using a different configuration, as well as set of nodes and storage configurations, and running different applications.
In addition to the previous requirements, it should be possible to include the dynamic setup procedure into existing workflows, as a HPC machine already offers a mechanism to schedule the execution of jobs on particular nodes. To use that mechanism, a user has to provide an estimated runtime and the number of resources to use for the job that should be started, e.g. cores, nodes or main memory per node, to the job scheduling system. The HPC job scheduler allocates the resources and starts the job.
When a job uses a Big Data framework, this framework has to run as a part of the job. For such a job, the required framework processes must be started before the user can run an Big Data application using all the benefits of the frameworks together with other software available on the HPC machine. When the cluster is not required any more because the work is finished it is stopped automatically and the used resources are freed and given back to the scheduler. Figure 1 visualizes the described process schematically.
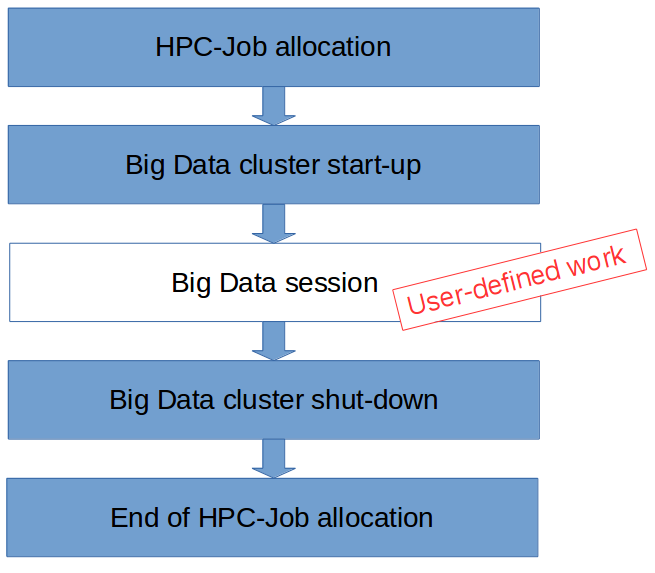
Using the pattern shown above, the process of starting a cluster dynamically in the data center can be extended to support not just one Big Data framework, but many different settings. Hence, a user can use Apache Flink and Apache Hadoop easily and even in parallel on the cluster. This makes it easier to test different setups and hardware configurations. With that, users are not required to install and maintain different frameworks themselves.




funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
