May 7, 2021
Embedding Assisted knowledge Graph Entity Resolution (EAGER)
Research
Entity Resolution
Let’s say you’re researching something on George Bush and look at different sources about him. First you have to make sure, every source you’re looking at is talking about the same person. Is it George H.W. or George W.? So in each source you check for their details e.g. their names and birthdate. What you’re doing there is what’s called entity resolution: determining which entities (in this case “George Bush”) refer to the same real world entity. The research in this field reaches back a long time already, but has usually focused on traditional databases or tabular data.
Knowledge Graphs
In recent years structuring data in so-called Knowledge Graphs has become a popular approach, not least due to its use by Google, Wikipedia, Facebook and many others. It’s what gives you the info box on the right when you search e.g. for a person or city in Google or Bing. Its idea is to store things (entities) as nodes in a graph that are linked via relationships.

In general they are able to represent their data much more flexibly than traditional databases and even entirely new types of facts can be added more easily without affecting the rest of the data. Now, what if we are given two different Knowledge Graphs and want to find all the entities in which they overlap? The flexibility of Knowledge Graphs we talked about before means most assumptions of traditional entity resolution don’t hold true anymore here and we need to come up with a few new tricks.
Entity Embeddings
The field of entity resolution in Knowledge Graphs is still relatively new. In order to mitigate the issues of having to deal with the flexibility of the data a lot of research has focused on entity embeddings. An embedding is a representation of an entity as a vector which tries to preserve the semantics of this entity. You may have heard of word or document embeddings elsewhere and it’s basically the same idea for entities in knowledge graphs.
If you have such an embedding for both of the knowledge graphs you’re trying to compare you can simply check how similar the vectors for each pair of entities are, i.e. how close they are in the embedding space. With entity embeddings producing reasonable results and traditional resolution techniques still having its merits as well, can we somehow make use of both? This is where EAGER comes in.
EAGER
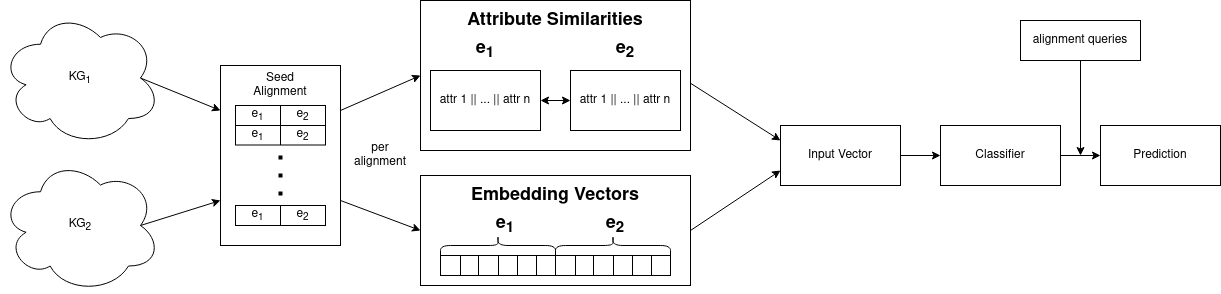
EAGER stands for Embedding Assisted knowledge Graph Entity Resolution. You can find our paper here. It recently got accepted at the Second International Workshop on Knowledge Graph Construction. EAGER takes pre-computed entity embeddings and different attribute comparisons and combines them into a single entity-pair-representation which can be fed into a classifier to determine whether two entities from each knowledge graph are the same or not. To keep things as simple as possible and proof that the idea is workable, we simply concatenated all attributes of each entity into a single string and compared these strings using different similarity measures. The figure below shows a summary of our approach.

The beauty of this model is that it is entirely modular and almost every piece in it can be swapped out and experimented with. So what are the parts of this and where do they come from? Let’s start with the attribute similarities. As mentioned above, we simply concatenate all attributes for each given entity into a single string. We then used three different similarity measures on it: Levenshtein, Generalized Jaccard and Dice. Note, that we could use any number of other similarity measures here or in fact use anything that will give us some meaningful set of numbers – think e.g. document embeddings. You could argue that simply concatenating all attributes into one long string is a bad idea. Why not compare names or addresses of entities directly? Since, from a machine point of view, we can’t be sure which attributes are the ones we care about, let alone which ones correspond between two different knowledge graphs. This problem is called schema matching and doesn’t have a simple solution in this case.
The second big part in our approach are the entity embeddings – since we are “embedding assisted”. For this part, we didn’t create any new entity embedding techniques ourselves but rather made use of a variety of existing models. We experimented with three different models, called BootEA, RDGCN and MultiKE. We are not going to go into too much detail here, but each of these has a very different approach to creating entity embeddings but they all achieved state-of-the-art results on a number of test datasets. MultiKE, which tries to make use of as many different aspects of knowledge graphs rather than focussing on one or two, usually worked out best for us. What all three models have in common, is that they base their decision of whether two entities are the same on the direct comparison of their embeddings. We do that, too, but also keep both embeddings and concatenate them with our attribute similarities. Now we have one big vector that we can use to train our classifier. Again, the exact type of classifier is not fixed here. We decided to experiment with a Random Forest and a Multi Layer Perceptron, both of which are well established and powerful classifiers in the machine learning world.
Results
So, does this actually produce any good results? We used a number of benchmark datasets, some using subsets of existing knowledge graphs (taken from YAGO, DBpedia and Wikidata) and some created ourselves by converting tabular data into knowledge graphs. Our experiments showed that using entity embeddings and attribute similarities together performs better, than using either on their own. This is especially true for the knowledge graph datasets. We then compared our different versions of EAGER with existing state-of-the-art entity resolution techniques, called Magellan and DeepMatcher. For the tabular datasets we achieved competitive results, and we could significantly outperform the other approaches on the knowledge graph datasets. Where do we go from here? We’ve proven that already a very simple way of combining entity embeddings with attribute similarities can yield superior results for entity resolution on knowledge graphs. Since our approach is very modular and flexible we can swap out any of the parts we’ve described so far for something new and see which one works best under which circumstances. We still need to find a way of being able to automatically find all corresponding entity pairs in two knowledge graphs, since we can currently only predict whether a given pair is equal or not. Future work will therefore consist in researching techniques to obtain entity pairs that we can present to our trained classifier.
Authors: Jonathan Schuchart, Daniel Obraczka


funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
