
CORAL
Title: Constrained Retrieval Augmented Language Models (CORAL)
Project duration: 10/2024 – 09/2027
Research Area: AI Algorithms and Methods, Understanding Language
Note: CORAL is not a project of ScaDS.AI Dresden/Leipzig, but associated members of ScaDS.AI Dresden/Leipzig are involved in the project.

The practical use of large language models (LLMs), is often limited by constraints such as among others high computational costs, legal requirements for training data, or traceability of generated texts. The CORAL project addresses these challenges, aiming to develop methods for constructing and using language models that operate under legal, technical, and qualitative constraints. To this end, we systematically explore methods for constrained training of LLMs and retrieval-augmented text generation. Together with our (associated) partners from the finance and cultural sectors, we also study the transferability and generalizability of these methods and models.
Aims
The research project CORAL aims to investigate methods for the construction and use of LLMs that are subject to legal, technical, and qualitative constraints. With the fulfillment of legal requirements for the training data of LLMs and the referential provenance of the generated texts, our focus is on two central criteria that are indispensable for the professional use of LLMs.
Problem
We examine whether practically usable language models can be trained on texts that are only available in various restricted forms. In addition, we develop methods to generate texts that incorporate domain knowledge and provide source references. In particular, the reproduction of training data should be avoided, while accurately referencing the specified sources. These methods will be evaluated through extensive experiments and tested in collaboration with partners from the financial sector, GLAM institutions, and industry.
Practical example
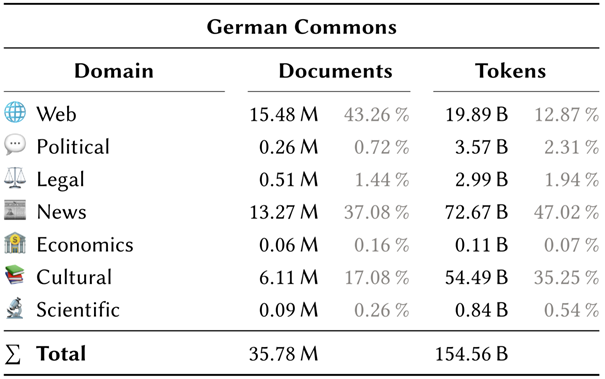
One recent result is German Commons, the largest collection of openly licensed German text to date. German Commons is a dataset that can be used to train language models, a process that requires large amounts of text, often sourced from web crawls with unclear licensing. In contrast, German Commons was carefully curated from verifiably licensed training data, enabling the development of truly open German LLMs.
- Data: https://huggingface.co/datasets/coral-nlp/german-commons
- Code: https://github.com/coral-nlp/llmdata
Technology
Our research focuses on both encoder and decoder models, each suited to different applications. Decoder models, the technology behind chat assistants such as ChatGPT, have attracted the most attention recently. While their improvements have been remarkable, issues such as high training costs, uncertainty about licensing of training data, or risk of text reproduction persist. We aim to train such models under constraints, unlocking new applications and making LLMs more widely accessible.
Outlook
Innovative results and insights are expected in three key areas of language model development and use across society, science, and industry:
- consideration of previously restricted training data
- model architectures that incorporate constraints, such as preventing the reproduction of training data
- referencing relevant and reliable sources on which the generated text is based
The exemplary transfer of these approaches will clearly demonstrate both their flexibility and effectiveness.
Publications
- Lukas Gienapp, Christopher Schröder, Stefan Schweter, Christopher Akiki, Ferdinand Schlatt, Arden Zimmermann, Phillipe Genêt, and Martin Potthast. The German Commons – 154 Billion Tokens of Openly Licensed Text for German Language Models. CoRR, abs/2510.13996, October 2025.
- Lukas Gienapp, Martin Potthast, Harrisen Scells, and Eugene Yang. Topic-Specific Classifiers are Better Relevance Judges than Prompted LLMs. CoRR, abs/2510.04633, October 2025.
- Lukas Gienapp, Niklas Deckers, Martin Potthast, and Harrisen Scells. Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins. In 15th International Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR 2025), July 2025. ACM.
- Jan Heinrich Merker, Maik Fröbe, Benno Stein, Martin Potthast, and Matthias Hagen. Axioms for Retrieval-Augmented Generation. In 15th International Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR 2025), July 2025. ACM.
- Lukas Gienapp, Tim Hagen, Maik Fröbe, Matthias Hagen, Benno Stein, Martin Potthast, and Harrisen Scells. The Viability of Crowdsourcing for RAG Evaluation. In 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025) , pages 159 – 169 , July 2025 . ACM.
- Julia Romberg, Christopher Schröder, Julius Gonsior, Katrin Tomanek, and Fredrik Olsson. Have LLMs Made Active Learning Obsolete? Surveying the NLP Community. In CoRR, abs/2503.09701, March 2025.
More information
Team
Lead
- Prof. Dr. Gerhard Heyer (Institut für Angewandte Informatik e. V.)
Team Members
- Lukas Gienapp
- Christopher Schröder
- Prof. Martin Potthast
- Prof. Gerhard Heyer
Partners
- Institut für Angewandte Informatik e. V.
- University of Kassel
- Anhalt University of Applied Sciences
- German National Library
Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
