Machine Learning made easy!
Start training your own machine learning models today. You can use asanAI in any browser of your choice - and it is completely free to use!
The approximation of simple functions with asanAI is really easy. On this page, we show you how the approximation of simple functions works and how to do it yourself. Take for example the following data:
x1,x2,y1,y2
5, 1, 6, 12
10, 2, 12, 24
15, 3, 18, 36
20, 4, 24, 48
25, 5, 30, 60
30, 6, 36, 72
35, 7, 42, 84
40, 8, 48, 96
45, 9, 54, 108
50, 10, 60, 120
We have no idea what the function that results in this data may be. For this example, we chose Problem type -> Data Classification. We get a default network with the layers and 3, 4 and 1 neurons respectively. We chose X&Y-Data -> own, and then Data type -> CSV. Then, we chose both y1 and y2 as Y.
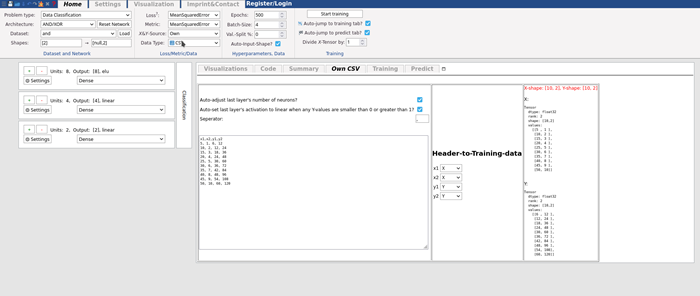
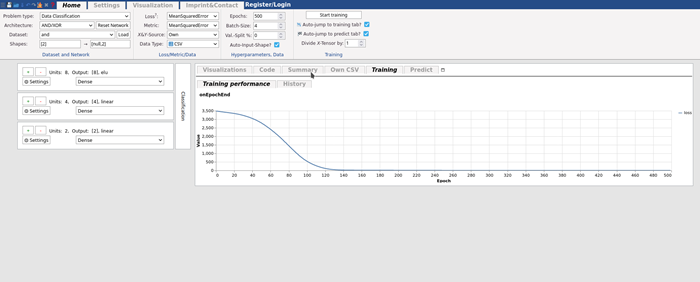
Now, we can use the loss Mean Squared Error. This penalizes errors more than MAE, and works well with such types of data. Then we click Start Training. In the graph that the training loss decreases. After 500 Epochs, the default, is at about 0.004, which is okay for most use-cases. We could have stopped the training earlier to save time, when it stopped decreasing a lot.
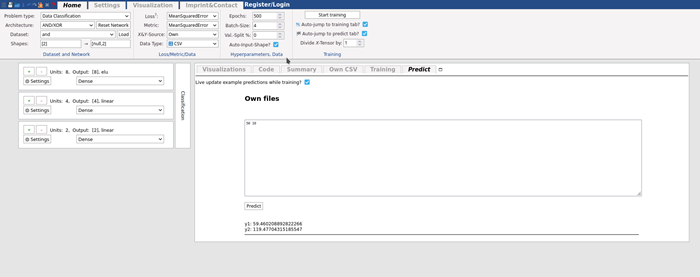
In the predict tab, you can enter example data. We know that [50 10] should give us [60, 120]. We can enter “10 50” to see what the network gives us for this:
y1: 59.460208892822266
y2: 119.47704315185547
This is very close to what it should be. We can now enter data to it it has never seen, such as [60, 20]. The internal equations that underly the data give us the results [80, 160]. The network gives us:
y1: 82.96539306640625
y2: 157.47305297851562
This is very close to the actual values. Remember: The network has never seen this data, but yet very accurately predicts them. If the result is very far off, the network may not be complex enough to approximate this function. You can add more layers to the network to make it able to detect more complex patterns.

Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
