
January 2, 2017
Introduction to Privacy Preserving Record Linkage
Research
Many companies and organizations collect a huge amount of data about people simply by offering their services in form of online applications. A more official way to gather such data is asking the people in printed forms. For example, this strategy is followed in hospitals and administration. In both cases each data owner holds information that cover only one or few aspects of each person.
However, analyzing such data and mining interesting patterns or improving decision making processes generally require clean and aggregated data which are held by several organizations. Record linkage operates as a preprocessing step for these tasks. The main goal here is to find records which refer to the same real world object or person. Such records are stored in different databases. This process finds application in many areas like healthcare, national security or business. In healthcare for example, linking records from two or more hospitals allows the adaptation of disease’s treatment of patients.
The main impediment when linking person related data across many organizations is the privacy aspect. Several countries processing such data are subject to strict privacy policies. Those policies include rules regarding the storage of data and whether that data can be exchanged with third parties. Privacy Preserving Record Linkage (PPRL) presents techniques and methods to efficiently link similar records in different databases without compromising the privacy and confidentiality.
Example
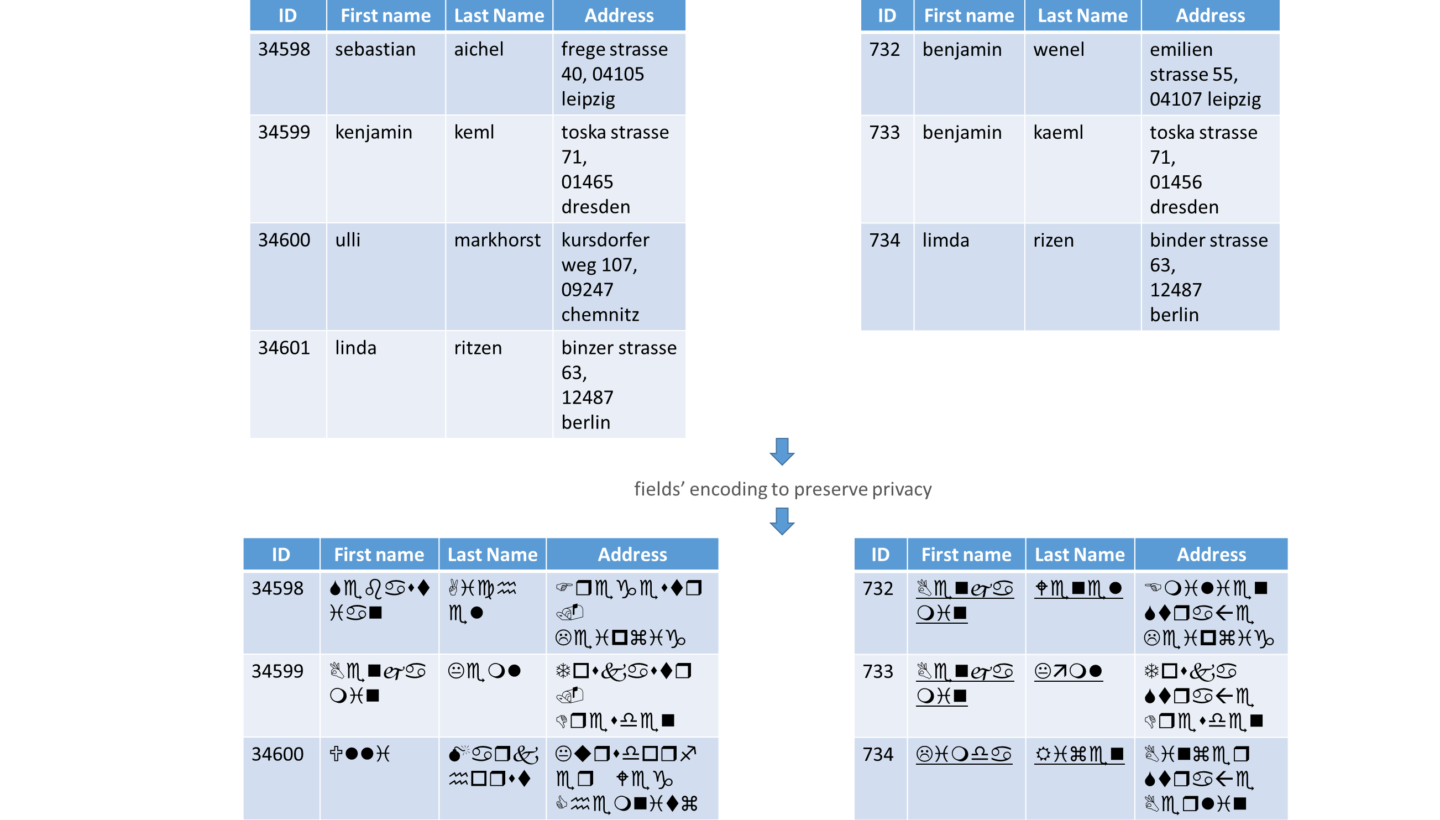
An example of PPRL in healthcare area is illustrated in Fig.1. Two research groups from two different hospitals are interested for possible correlation between two diseases:
- Diabetes Type 2
- Alzheimer.
The database of hospital 1 contains records about patients generally suffering from diabetes and other cardiovascular diseases. The database of the second hospital stores records about patients afflicted with different forms of dementia.
Since there are no unique IDs to identify persons in both databases, the data holders first agree on some fields to be used in the linkage. These fields, known as Quasi-Identifiers (QID), have the property that together they enable the identification of a person, e.g. in the databases of Fig.1 fields like first and last name, date of birth and address are well suited to be used as QIDs. The other type of fields, holding highly sensitive data about patients, should and cannot be used with the QIDs in the linkage process because they are very private and have no added value in the linkage.
For example if we consider the records 34599 and 733 from hospitals 1 and 2 respectively, the only fields we need in the linkage process are first and last name, and the address. The other fields, weight and disease, are on the one side sensitive and should not be disclosed, and on the other side they are very dissimilar to be compared with each other (e.g. diabetes and Alzheimer). After the normalization/standardization of the QIDs they are encoded/encrypted in a way that allows their comparison (preserves similarity) without disclosing the identity of the persons they represent (preserves privacy).
The following step is to compare the encoded records and to classify them in match and non-match. Now the data owners know the IDs of the matching records and they can exchange some sensitive fields of the respective matches to continue their research. For example the data owners know that the pairs (34599 – 733) and (34601 – 734) are matches and after exchanging some of their sensitive information (e.g. disease) they can deduce that there is possibly a correlation between diabetes type 2 and Alzheimer.
An important question after the execution of such a process is: which information is gained by each data owner about the other’s database?
- The first kind of information know by each data owner are the matches. Data holder from hospital 1 knows that patients with ids 34599 and 34601 (idem for hospital 2) both are suffering from Alzheimer, but we can argue that this was the goal of the linkage process.
- Furthermore each data holder knows that its own non-match records (patients) do not suffer from any disease stored in the other database (e.g. record 34589 in database 1 does not suffer from any kind of dementia). This kind of information gain (or leak) is unavoidable in the record linkage process.
- The last and most important information that must not be disclosed are the other party’s non-matches, i.e. that no data holder knows the non-match records of the other (data holder from hospital 1 does know nothing about the records 732 stored in database 2).
Record Linkage
The main challenges encountered when linking two or many sources are scalability to large datasets and high result’s quality. The scalability problem is due to the ever-growing size of the datasets to be linked and the quadratic nature of the record linkage process.
Hence, the naïve way of comparing records dramatically affects the runtime of the process and is unfeasible for large datasets. Therefore, refined solutions like blocking/indexing and partitioning are required during the process. The result’s quality of record linkage depends on several factors, including like the quality of the input data the followed blocking strategy and the used classifier. The aim is to reduce both the number of false positive (number of non-match pairs which are labeled as match) and false negative (number of match pairs which are labeled as non-match). Record linkage overcomes these challenges by following several steps outlined in Fig. 2.
Pre-processing
Since the different datasets to be linked are heterogeneous and sometimes dirty, the data owners have to agree on some fields to use in the linkage process. Generally these fields, also called Quasi-Identifier QID, have a high selectivity and together allow the identification of a record. Furthermore the data owners define a set of rules to transform these fields in a standard form, e.g. the way to deal with missing values, case sensitivity and abbreviations. For example data holders in Fig. 1 agreed to use three common fields (first and last name and address) then they normalized them (lower case, ä to ae …).
Blocking
As explained above the main goal of blocking is to mitigate the quadratic nature of the linkage process. It is quite obvious that for each record from one dataset only a small set of records from the other datasets constitute candidate matches that must be checked for similarity.
To save comparisons between dissimilar records one can put “probably similar records” in the same blocks, so that only records within one block will be compared with each other. A block is defined by a key, which is shared by all records belonging to it, e.g. the same zip code or some specific letters in the name. Other methods use filter techniques based on some characteristics of the records, the used similarity function and its threshold to prune dissimilar records before comparison. Finally, in the case of Big Data, the aforementioned strategies can be combined within a parallel environment to further improve the runtime.
Similarity computation
Records from the same block or partition are compared with each other using one or many similarity functions. The output of this computation is either a unique value, generally normalized between 0 and 1, that expresses the similarity degree between two records, or a vector of normalized similarity values. The latter case occurs when for different attributes different similarity functions are used.
Classification
The similarity values between pairs of records are used to assign them to a class:
- match
- non-match
- possible match
There are several classification methods depending on the input data and the use case, e.g.:
- threshold-based
- rule-based
- (un)supervised learning
- probabilistic method proposed by Fellegi and Sunter.
Evaluation
The aim is to evaluate the record linkage process w.r.t. its runtime, its complexity and its result’s quality. Runtime and complexity are much related and depends generally on the efficiency of the blocking method. The blocking scheme should exclude as many dissimilar pairs as possible without causing a runtime overhead. The quality is expressed by two values from the Information Retrieval, precision and recall. Beside the number of true matches precision and recall are influenced by the number false positive and false negative respectively.

Privacy Preserving Record Linkage
Linking person related data adds a new challenge to the two ones already presented, privacy. Such data contain highly sensitive information about people and their process is generally restricted by law. Therefore, new methods and technique must be integrated in the standard linkage process to overcome this challenge.
Privacy Preserving Record Linkage follows almost the same steps described above. However, several modifications are introduced to fit in the privacy context (shown in red in Fig.3). We start by presenting which kind of modification is needed in each step to preserve privacy. Practical realizations of these modifications will be presented later on (some in this post and others in future posts).
At the beginning, in the preprocessing step, the cleaned and normalized records must be encoded/encrypted by the data owners. Encryption techniques are discussed later on. The main challenge when encoding records is to make them anonymous while preserving their possible similarity. In the blocking phase new techniques must be developed. The reason is that traditional methods using (part of) fields may disclose the identity of the person. Generally, the same techniques used to compare clear text records are used for encoded ones. However, not all classification methods can be used. For example supervised learning methods need a ground truth that is not always available in PPRL due to privacy concerns. The evaluation of result’s quality is even more challenging due to the lack of golden standard.
Note that the steps shown in Fig. 3 present a general workflow of PPRL. Depending on the followed protocol (explained below) some steps might be differently executed or even missing.

PPRL protocols
A PPRL protocol describes the steps to follow by each involved party to carry out the linkage process. The protocols mainly differ in the number of involved parties and the privacy degree.
Two-Party protocol
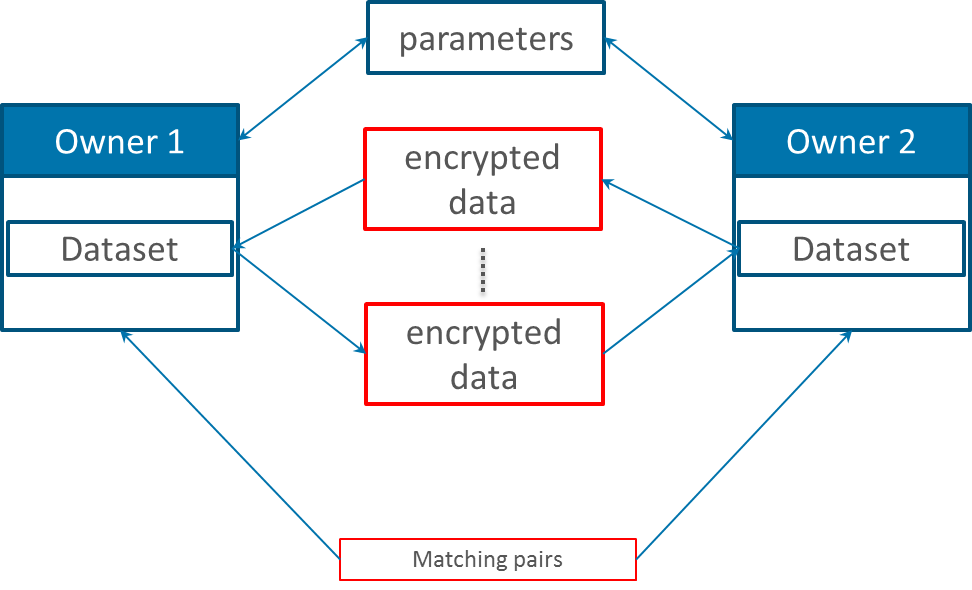
This protocol has the minimal possible number of parties taking part in the PPRL process, two data owners. To find matching records the involved parties exchange some messages about their records without disclosing them. One know way to realize this is to use Secure Multiparty Computation (SMC) introduced by Yao. In our case the input of such a computation are two private records from two parties and a public similarity function (match or non-match).
The goal is to compute the similarity between these two records by exchanging cryptographic messages between the data holders. A computation is successful, if the parties calculate the function but none of them knows the other’s data. Although this protocol is more secure compared to others, its main drawback is scalability. Each record from one source must be compared with all other records from the other source (quadratic complexity). Furthermore, the comparison of each pair of records needs the exchange of a relative high number of messages.
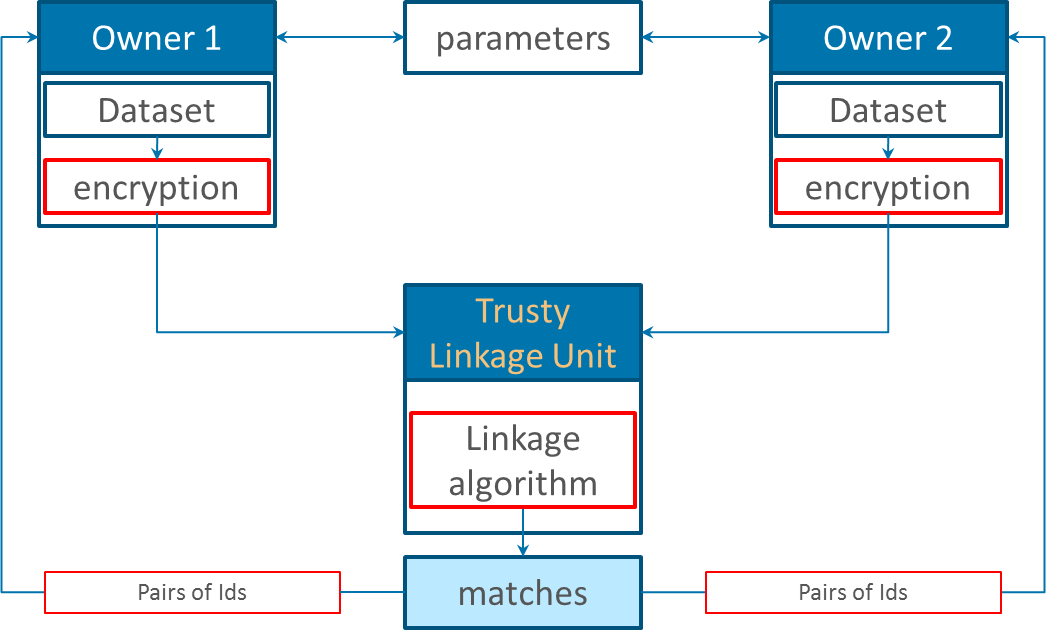
Three-Party protocol
In this protocol a trusty third party, also known as linkage unit (LU), is involved in the linkage process. First, the data owners preprocess and encode their data by their own. Then both parties send their encoded record to the LU which run an adapted linkage algorithm. At the end the UL returns only the IDs of the matching records to the data owners. In contrast to the two party protocol, this protocol is less secure due to the extra LU. As a plus, the same LU can use many blocking and/or parallel techniques to improve the scalability and runtime.
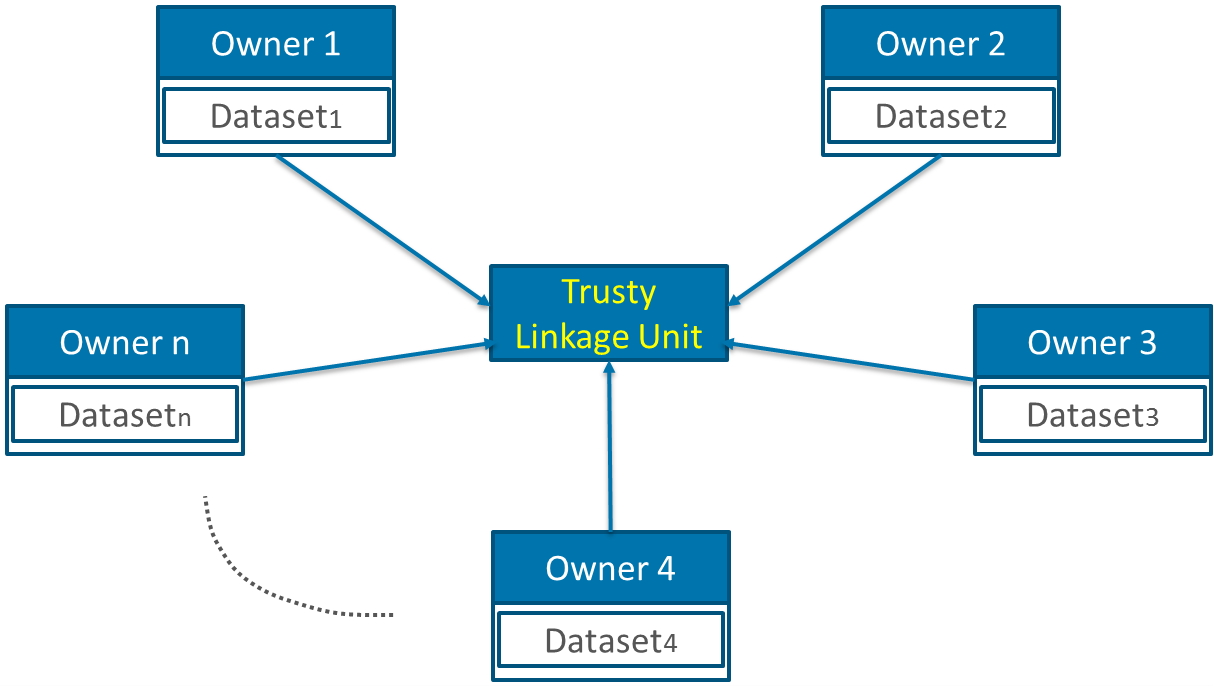
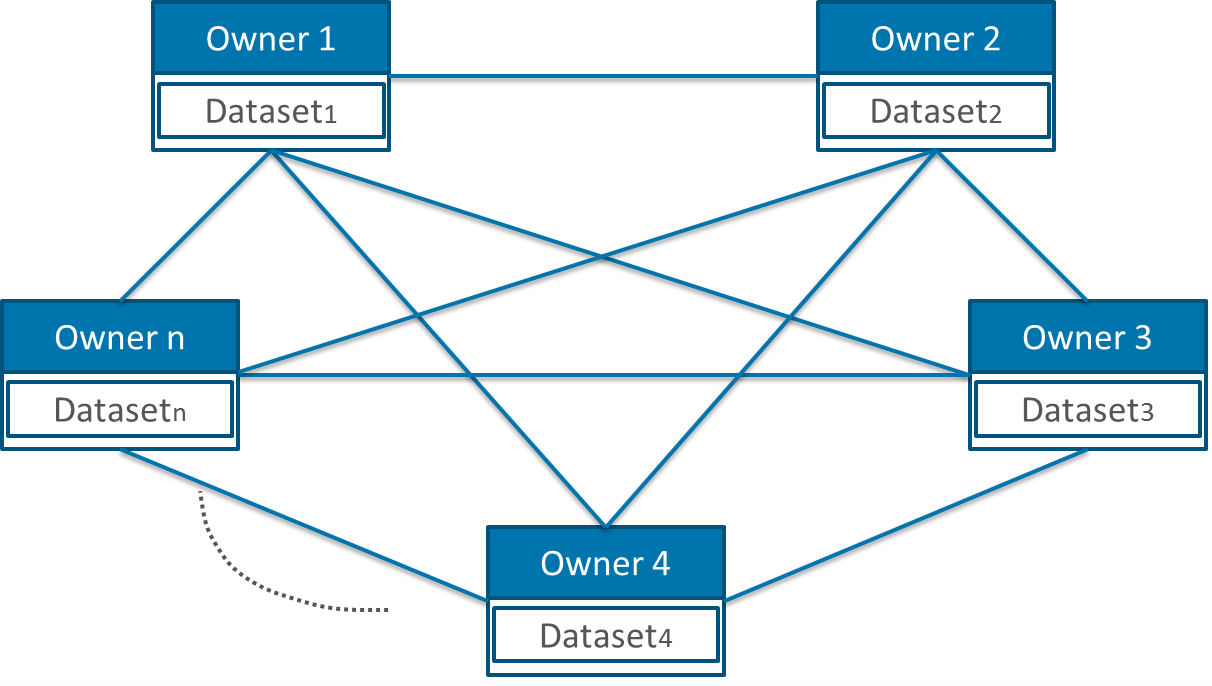
Multi-Party protocol
This kind of protocol is a generalization of the two above mentioned protocols. Here, more than two data owners are involved in the linkage process. This can be realized with or without a LU. The main difference is the kind of matches we are interested in. The first case is pretty easy and try to find matching records present in all datasets. To find matches present in sub-sets of all the datasets is the more difficult case aim.
Data anonymization
To preserve privacy and confidentiality several data masking/encoding techniques for PPRL were developed. In the following we describe some of them and show for which kind of protocol they are suitable or rather in which step of the PPRL process they occur.
Commutative encryption
Commutative encryption is a well know encryption scheme used in three-pass-protocol to exchange private messages between two parties without sharing any key. The commutative encryption scheme can be used as special case of secure multi party computation to implement some basic operations like set intersection. This is a fundamental operation to compute the similarity between two records represented as sets of tokens. The basic idea of commutative encryption is the existence of a function f that satisfies the commutative property:
fk1(fk2(x)) = fk2(fk1(x)), where k1 and k2 are two private keys owned by the two parties respectively and x the message to exchange. An example of such a function is: fk(x) = xk mod n.
Let’s now show roughly how commutative encryption can be used in PPRL. Two parties Alice and Bob have their own encryption and decryption keys ki and di respectively. For each pair of records (represented as sets of tokens) Alice and Bob execute the following steps:
- Each party encrypt the elements of its tokens’ set using its own encryption key: Ei(k,t)::encrypt(token t using key k).
- Alice sends its encrypted tokens EA(ka,ti) to Bob, and Bob sends its encrypted tokens EB(kb,ti) to Alice
- Alice encrypts Bob’s tokens using here key, i.e. EA(ka,EB(kb,t)) and sends the pairs < EB(kb,t), EA(ka,EB(kb,t))> back to Bob.
- Bob encrypts Alice’s tokens using his key, EB(kb,EA(ka,t)),
- Bob decrypts its part from the pairs received from Alice, i.e. <t, EA(ka,EB(kb,t))>, because E is commutative he can check whether EA(ka,EB(kb,t)) = EB(kb,EA(ka,t))
This kind of computation, although very secure, still have scalability problems. From the above algorithm one can see the number of exchanged messages between the parties to compare just one pair of records, and these steps must be carried out for all pairs (quadratic complexity).
Hash function
A very simple way to “guarantee” privacy is to use hash function to generate hash values of records then to compare them in a private way using two or three party protocol. Because such encryption scheme is vulnerable to dictionary attacks, one can enhance the security by using keyed hash functions like SHA-1. However, this kind of data anonymization has the main drawback that it allows only to check whether two records are equal or not (equality and not similarity) which is feasible when dealing with dirty data.
Phonetic encoding
Phonetic encoding is widely used in record linkage and database systems to generate blocks of candidates. It can also be used in PPRL to overcome the scalability problem. The basic idea of phonetic encoding it to produce a code for each name based on it pronunciation while tolerating small typos. Soundex for example generates codes of length four (One character followed by 3 digits), e.g. Carol and Carrell share the same code C640. Note that phonetic encoding is language dependent.
Bloom filter
Bloom filter was originally presented by Bloom to efficiently check set membership. Its adaptation for PPRL was proposed by Schnell in a three-party protocol. The workflow to encode two record from two different parties into a bloom filters is and illustrated in Fig.7. First the QIDs of each record are tokenized to n-grams. Then starting with an empty bit array of length l, the elements of each set of tokens are mapped into the same bit array using k hash functions.
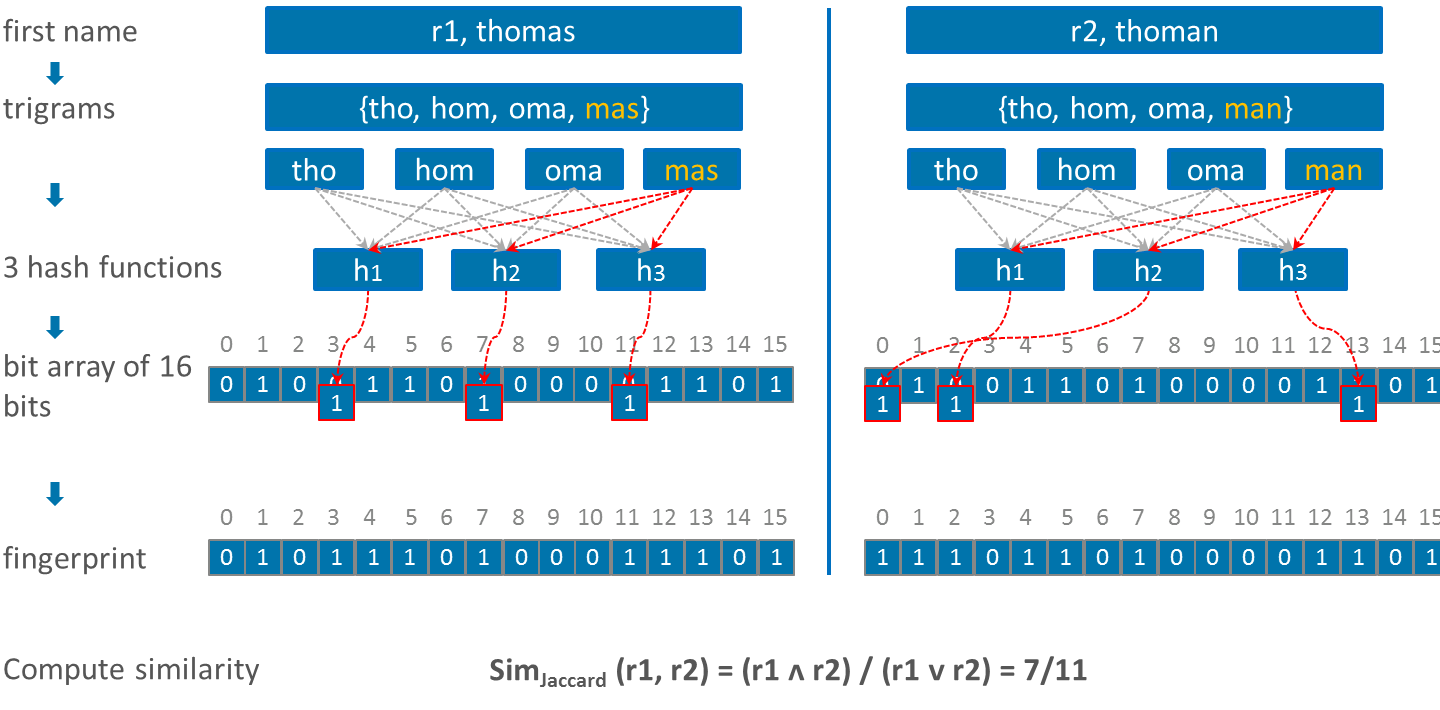
When appropriate parameters are used, like length of the bit array and the number of hash functions, bloom filter can provide high privacy and result’s quality. Furthermore the authors proposed some methods to harden it.
Privacy Preserving Record Linkage in our Living Lab Lecture
You want to know more? Watch our Living Lab lecture on Privacy-Preserving Record Linkage on our YouTube channel.


funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
