
September 6, 2016
Automated settlement detection in topographic maps
Research
The analysis of settlement structures, building fabric and building use, is one of the core tasks of spatial and landscape planning. Relevant fields of application are e.g. urban planning measures, planning of traffic routes and infrastructure, nature conservation planning or the preparation of hazard maps in case of natural disasters. The largest centralized and at least Europe-wide available data basis for such investigations are topographic maps. Both current and historical maps play a role. The latter are used for the analysis of historical developments or long-term monitoring of settlement structures and land use. A crucial step in the analysis of cadastral material is the recognition of settlements. This includes the division of the investigated region into settlement and non-settlement areas (automatic segmentation of topographic maps). In this blog post, we explain to you how automated settlement detection in topographic maps works.
Objective
The objective of the diploma thesis “Semantic Segmentation of Historical Topographic Maps”, completed by Daniel Schemala in March 2016, was to develop a software tool that allows the recognition of settlement areas in scanned maps.
Methodology
The methods used in this project are from the field of machine learning. Thereby – qualitatively spoken – a computer program is learned with the help of maps with known settlement distribution in order to be able to segment also new maps of unknown settlement distribution after this learning step. First, based on the color values of the individual pixels, the probabilities are calculated with the help of an algorithm based on decision trees (“decision forest”). It calculates whether each of the pixels belongs to a settlement or not.
In principle, this method alone could be used for segmentation. But it needs to be mentioned, that it generally does not provide useful results in the case of topographic maps. The reason is, that the prior knowledge that settlements form larger contiguous areas has been disregarded. In order to take this information into account and thus obtain contiguous settlement areas (as they are found in reality), a “Conditional Random Field” was applied as a second step. Details on the methods as well as further references can be found in Daniel Schemala’s diploma thesis.
Results
“Lakaseg”, a software which was developed in the context of the diploma thesis, has been tested on historical map material (“Messtischblätter” from about 1890) and provides satisfactory results. The model parameters have to be chosen appropriately by the user to achieve optimal results. The software is also freely available and can be downloaded – together with instructions on how to install and use the program – from the following link: https://github.com/EinfachToll/Lakaseg
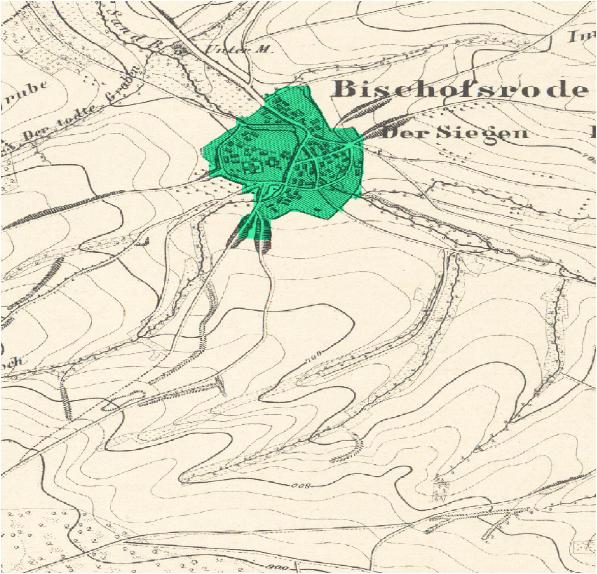
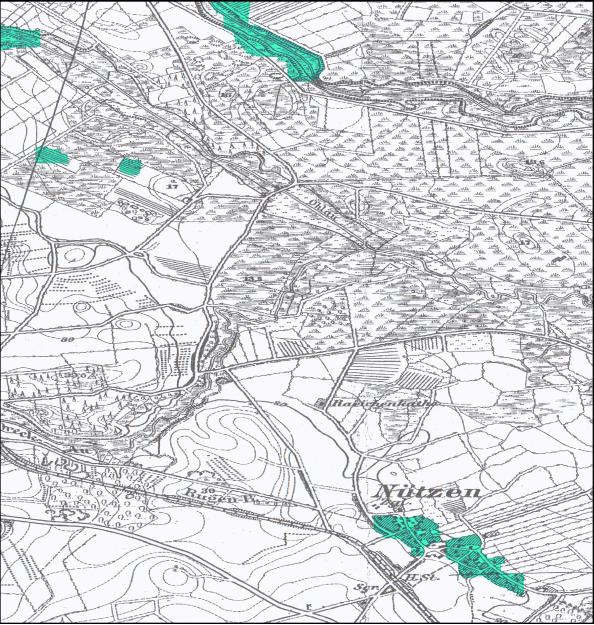
Outlook
Currently, the software is being tested on the high-performance computer “Taurus” as part of the project. First of all, a runtime comparison between Taurus and a common PC will be carried out. As a next step, a Germany-wide, area-wide segmentation of the survey table sheets from 1870-1945 is planned. This requires computing power and storage capacity that is only available on a mainframe architecture. The map material is managed by the Saxon State and University Library (SLUB). Discussions are currently underway regarding a cooperation for the evaluation of the maps.
Contact
- Daniel Schemala
- Dmitri Schlesinger
- Hendrik Herold
- Peter Winkler




funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
