
January 17, 2017
Big Data reference architectures: Are they really needed?
Research
Big Data Reference architectures are a key research topic in business information systems. They try to simplify software development by reusing architectural and software components. But reusability leads also to a trade-off in making reference architectures on a higher level to reuse it in many domains and applications. Or to concentrate them on a subject and hence easier to reuse. In this blog post we discuss, whether big data references architectures are really needed. Our hypothesis is that current big data reference architectures are not sufficient to provide real benefit for implementing big data projects.
What are Big Data reference architectures?
In scientific literature there are a lot of different reference architectures for specific domains or problems as well as approaches for definition of the term reference architecture. According to (Dern 2006) reference architectures unify groups of existing information systems and differ to common IT architectures in the abstraction level and usage in an organization. A more technical perspective view on the term uses (Trefke 2012), as he states that software components and their interactions are the core of a reference architecture to map the functionalities of reference models. Special characteristics given by the problem or domain use case are abstracted and so generalized. In a similar way the widely used Rational Unified Process (RUP) for software development describes the term as a “predefined architectural pattern, or set of patterns” that are already instantiated and proven in business or technical settings (Reed 2002).
These definition approaches focus on software perspective of a reference architecture. In a broader view the “whole” system including processes, methods, etc. have to integrated in such an architecture. The definition of (Cloutier et al. 2010) includes these aspects and further argues that a reference architecture “capture the essence of existing architectures, and the vision of future needs and evolution to provide guidance to assist in developing new system architectures.” In addition, this work proposes two key principles for the design of reference architectures (Cloutier 2010):
- A Reference Architecture is an elaboration of company (or consortium) mission, vision, and strategy. Such Reference Architecture facilitates a shared understanding across multiple products, organizations, and disciplines about the current architecture and the vision on the future direction
- A Reference Architecture is based on concepts proven in practice. Most often preceding architectures are mined for these proven concepts. For architecture renovation and innovation validation and proof can be based on reference implementations and prototyping.
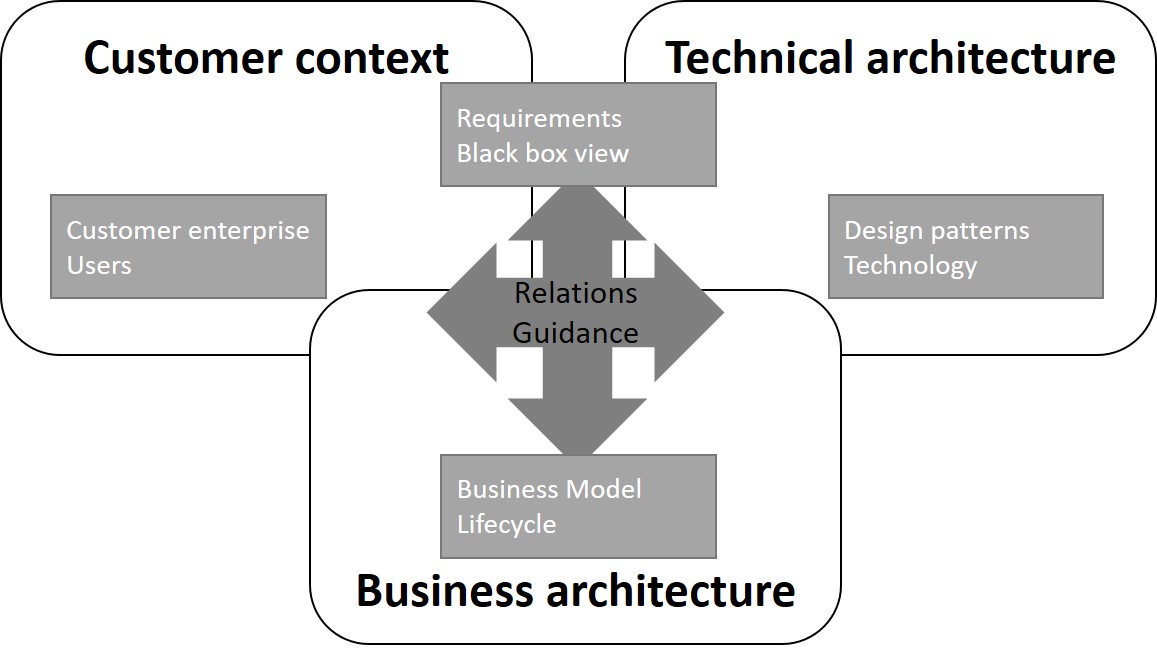
The common denominator in the definitions in the definitions are the terms abstraction, proven, universality and domain. Abstraction means that specific aspects, e.g. less important constraints, of the formulated problem or use case are not incorporated in the solution architecture. Most of the definitions speak about proven concepts which are integrated. So only artefacts that solved a sub problem, were already implemented and especially evaluated in practical settings can be used. Proven concepts can also mean that new concepts are developed that are based on experiences in similar problem cases. The other two terms – universality and domain – are in opposition to each other. Every reference architecture is located in a domain, no matter if its focused on a problem or a business domain. But on the other hand one overall goal of reference architecture is universality, which means generalization of specific problems.
This conflict is still an open problem in research, because of the trade-off between the universality of a specific problem and the usability of a reference architecture. This manifesst itself in the ease of use of a reference architecture for an instantiation in a domain-specific problem. If the architecture is too universal, the reusability in other settings is quite good, but the instantiation in a specific use case needs lots of adaptions. But if the described reference architecture is too domain-driven and problem-specific the universality lacks and the scientific nature and research contribution is disputable. The benefit of such architecture models is that they are highly relevant in practice. Furthermore, for instantiation less adaption is needed.
Why are they needed?
In recent years’ software applications, organizations, business processes and hence the information systems being developed and used are getting more complex, e.g. in their scope and size. Also the environment of the information systems landscape in organisations become more dynamic. “Time-to-market” and “interoperability” are terms that describe key success factors not just for business companies; in healthcare, government, etc. these needs are highly relevant too (Cloutier et al. 2010). The goal of reference architectures is to decouple the effect that with increasing complexity of information systems the complexity of the development process increases.
First of all, reference architectures provide common taxonomies, grammars and architectural visions of the problem domain. These aspects help to simplify communication in complex project teams and in requirements engineering. Further, the documentation of large information systems on an appropriate abstraction level leads to better interoperability between different systems. It further helps to reduce efforts to adapt instantiations due to dynamics and changing environments. The most important goal for many companies for using reference architectures is the more efficient development process of software or information systems. The reusability of existing concepts (and in the best case implemented software modules) leads to significant decrease in development efforts. By the use and application of known and already proven patterns for the implementation, reference architectures mitigate risks that occur by implementing new systems from scratch.
Against this background various reference architectures were postulated in recent years. Most notable approaches are:
- the SOA reference architecture (Open Management Group 2011) for service-oriented architectures or
- the Cloud Computing reference architecture (NIST 2011) for cloud technologies and services.
These are published as de facto standards for their particular problem domain, constructed by national standardization organisations (NIST) or international industry consortiums. Other well-known approaches are vendor-driven and more domain- respectively technology-specific than the aforementioned. Examples are Business intelligence reference architectures by:
- IBM (2003)
- Forrester (2012)
- Big Data & Analytics Reference Architecture by Oracle (2013)
- Reference Architecture for Data Warehouses (Microsoft 2014)
Their intention concerning reusability is focused on deploying their products at different customers and to promote these products. Different perspectives take domain-specific reference architectures, like the:
- Smart Grid Reference Architecture (Smart Grid Coordination Group 2012) for intelligent power generation and distribution,
- the ARIS reference model for business process management (Scheer 1997) or
- the SCOR reference model for the efficient management of supply chains in manufacturing and logistics environments.
These are examples for business-oriented reference architectures that address besides the technical aspects of the IT systems also functional aspects of the domain and organizational aspects. Due to this more detailed view, the instantiation requires less effort, but the reusability is more restricted then the SOA or Cloud Computing reference architectures.
Which proposals for big data reference architectures are around?
The NIST provides another big data reference architecture (National Institute of Standards and Technology 2015). It also describes technical building blocks of big data systems, e.g. infrastructure components like storage, computing or network resources, but also surrounding components for the management of the resources, processing models or data organization. Despite it provides also functional architecture components e.g. for data collection, preparation, analytics or visualization, the abstraction level of this components – and the customer context – is quite high, while this means that it is highly reusable in many use cases the instantiation for a specific domain needs more effort. So the first key principle of Cloutier (2010) is broken, since a clear strategy description is missing. Further it only consists of a technical architecture, while customer context and business architecture are necessary RA building blocks (Cloutier 2010).
Nirmala and Raj (2016) describe different components of big data architectures, which are commonly used in organizations for big data analytics projects. They further outline several scenarios like text, stream or predictive analytics. But how these use cases relate to the technical components is missing. The approach further lacks in describing the functions of and interactions between the technical components as well as how the architecture can be used in different settings and problems.
Pääkkönen and Pakkala (2015) also present an approach for a big data reference architecture. It is derived from existing data analytics infrastructures of Twitter, Facebook and LinkedIn. It contains eight modules starting with data sources and storage up to the visualization and access to information. Further it provides mappings between this modules and existing big data technologies.
A more specific reference architecture for big data systems in the national security domain is proposed by Klein et al. (2016). In addition to the technical view, it contains modules of the NIST approach (2015), it integrates domain knowledge and use cases to the reference architecture and tries to include aspects of reference models. Hence it provides a technical and a customer context, they lack in details and doesn’t contain methods to close this gap. Further domain-specific aspects of the use case have no consequences for architecture components and functions or are not described in detail.
All of the presented approaches have modules for the collection, storage, integration & preparation, analysis and visualization of data, as well as the under- respectively overlying stakeholder, data provider and data consumer. There is little variation in this components and in the abstraction level of these components. The NIST approach is getting deep into technical details and describes sub-modules, such as:
- infrastructure
- resource orchestration
- processing models for big data analytics
On the downside, it lacks in domain and application details. Therefore, this approach can be seen as a meta reference architecture to derive domain-specific reference models for big data projects.
Discussion
Compared with domain-driven reference models like SCOR or ARIS the introduced attempts provide a more technical-oriented RAs and are far from describing detailed processes and best practices for solving specific business problems. Standardized approaches like (Open Management Group 2011) or (NIST 2011) have more fine-grained descriptions of the architecture modules and include in certain scope guidance for the instantiation. By comparing the big data reference architectures with existing business intelligence reference architectures it is remarkable that they have many components in common. Examples are modules for data sources, data integration and preparation as well as for data analytics and visualization. Apparent differences between both areas concern the focus in business intelligence on several aspects of metadata and information management, instead big data reference architectures include data processing aspects like processing models, infrastructure and resource management.
So why do we need explicit reference architectures for big data? Here are some arguments against!
- Opposed to business intelligence RAs, Big Data RAs differentiate (if any) in regarding infrastructure or data processing components. These building blocks are neglected in BI reference architectures because most BI or DBMS tools make this aspect transparent to the user.
- The differentiator of integrating unstructured or semi-structured in data sources in big data architectures is not still valid because business intelligence tools now provide capabilities for log or text mining too. Moreover, already IBM (2003) integrated unstructured data sources in their approach for a business intelligence RA.
- Most use cases used for motivating and designing a big data reference architecture are located in web-based business models or at least in the business domain. They don’t consider use cases from scientific areas, academia or healthcare. Integrating big data architecture aspects in the domain-specific RAs could solve this problem or the design of Big Data RAs for these domains.
- Generic architectures for big data systems only help identifying necessary technical components and hence for technology decisions. Domain-specific requirements and problems are on a lower abstraction level and indeed less reusable, but are more grounded on reality and hence need less effort for instantiation. The gap between technical-oriented reference architectures and those which are more domain-oriented gets obvious by comparing the approaches of (Klein 2016) and (NIST 2015). While the first is domain-specific for security domain, the latter is domain-agnostic and focus on technical components.
One argument on behalf a big data reference architecture is the non-consideration of real-time data like sensor data streams in business intelligence reference architectures. Despite, some BI RAs contain stream-based applications like business or complex event processing.
| Big Data Origin | Big Data target |
|---|---|
| Science | Scientific discovery |
| Telecom | New technologies |
| Industrie | Manufactoring, process control, transport |
| Business | Personal services, campaigns |
| Living environment Cities | Living environment support |
| Social media and Networks | Human Behaviour |
| Healthcare | Healthcare support |
Outlook
To come back to our hypothesis of the beginning, we explained why we think that the mentioned approaches are not sufficient for supporting big data projects. What is the conclusion and what should be future research outcomes to solve this problem? Since Big Data reference architectures barely distinguish from existing business intelligence reference architectures it might be reasonable to combine both concepts. The approaches can be merged and could lead to a Business Analytics reference architectures (BIRA).
Based on this “Big data meta architecture model” domain-specific reference models could be derived and instantiated. Table 1 shows possible domains and use cases for such reference architectures. Forrester research already tried to integrate Big Data in their BIRA for business applications but did not argue why (Evelson & Yuhanna 2012). Another research direction would be to design specific BDRAs for each domain and use cases without merging BI aspects. This would result in a higher number but lean architectures, which probably are easier to instantiate.
References
- Dern, G. (2006). Management von IT-Architekturen. Springer Fachmedien.
- Trefke, J. (2012). Grundlagen der Referenzarchitekturentwicklung, in: IT-Architekturentwicklung im Smart Grid. Appelrath, H.-J. et al. (Hrsg.), Springer-Verlag Berlin Heidelberg.
- Reed, P. (2002). Reference architecture: The best of best practices, IBM developer works. http://www.ibm.com/developerworks/rational/library/2774.html
- Cloutier, R., Muller, G., Verma, D., Nilchiani, R., Hole, E., & Bone, M. (2010). The concept of reference architectures. Systems Engineering, 13(1), 14-27.
- Open Management Group (2011). SOA Reference Architecture Technical Standard, http://www.opengroup.org/soa/source-book/soa_refarch/.
- National Institute of Standards and Technology (2011). NIST Cloud Computing Reference Architecture, http://www.nist.gov/customcf/get_pdf.cfm?pub_id=909505.
- IBM (2003). Business Intelligence Technical Reference Architecture, ftp://ftp.software.ibm.com/software/data/persontopersonprogram/lisbon/gosselin.pdf.
- Oracle (2013). Big Data & Analytics Reference Architecture, www.oracle.com/technetwork/topics/entarch/oracle-wp-big-data-refarch-2019930.pdf.
- Microsoft (2014). Reference Architecture (DW) – A Technical Reference Guide for Designing Mission-Critical DW Solutions, https://technet.microsoft.com/en-us/library/hh393514(v=sql.110).aspx.
- Smart Grid Coordination Group (2012). Smart Grid Reference Architecture. http://ec.europa.eu/energy/sites/ener/files/documents/xpert_group1_reference_architecture.pdf.
- Supply-Chain Council Inc. (2011). Supply Chain Operations Reference Model (SCOR) Version 10.0. www.supply-chain.org.
- Scheer, A.-W. (1997). Wirtschaftsinformatik-Referenzmodelle für industrielle Geschäftsprozesse, Springer.
- Nirmala, M. B., Raj, P. (2016). Big Data Computing and the Reference Architecture, in: Big Data: Concepts, Methodologies, Tools, and Applications: Concepts, Methodologies, Tools, and Applications.
- Klein, J., Buglak, R., Blockow, D., Wuttke, T. and Cooper, B. (2016). A reference architecture for big data systems in the national security domain. In Proceedings of the 2nd International Workshop on BIG Data Software Engineering (BIGDSE ’16), ACM.
- National Institute of Standards and Technology (2015). NIST Big Data Interoperability Framework: Volume 6, Reference Architecture. http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1500-6.pdf
- Pääkkönen, P., & Pakkala, D. (2015). Reference architecture and classification of technologies, products and services for big data systems. Big Data Research, 2(4), 166-186.
- Supply Chain Council (2012). Supply Chain Operations Reference Model Revision 11.0, www.supply-chain.org.
- Evelson, B. & Yuhanna, N. (2012). Forrester research – Craft Your Future State BI Reference Architecture. https://go.forrester.com/#/Craft+Your+Future+State+BI+Reference+Architecture/fulltext/-/E-RES82341


funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
