
June 30, 2026
Experiencing AI at the Living Lab: OUTPUT.DD and Dresden Science Night 2026
Living Lab
June 2026 was all about science communication. In Dresden, ScaDS.AI Dresden/Leipzig invited the public to explore the Living Lab at two different events: OUTPUT.DD 2026 and Dresden Science Night 2026.
OUTPUT.DD 2026
On June 25, 2026, OUTPUT.DD 2026 took place. Each year, the project show of the Faculty of Computer Science at TU Dresden creates opportunities for researchers and the public to exchange ideas about emerging technologies. Students, researchers, and industry partners present their projects and connect with a broader audience. Visitors can discover innovative technologies, learn about current research, and engage directly with the people behind the projects. ScaDS.AI Dresden/Leipzig presented four interactive exhibits that highlighted current developments in AI. The showcased projects included asanAI, Multicut, SQuAI, and Metis. Together, they demonstrated how AI research can address both technical challenges and societal needs.
Machine learning often appears complex and difficult to approach. However, asanAI aims to change that. The open-source platform enables users to experiment with machine learning directly in a web browser. Users train AI models using images, webcam input, CSV files, and other datasets. They don’t need programming experience or specialized software for it. Instead, they explore machine learning through an intuitive graphical interface.
Distinguishing objects from one another in images is a very difficult task for computers – because an image only consists of a number of pixels. These pixels are arranged in a grid, which the computer can break down into individual parts in order to assign individual pixels to an object in the image – for example a tree trunk, the crown of a tree or the sky in the background. In this process, similar pixels remain together, while pixels that differ from each other are separated. In this way, the computer is able to distinguish individual objects from one another. The multicut problem in computer science describes the task of cutting up a network of pixels as perfectly as possible – a major challenge! Compete against the computer and try to solve the problem yourself in our multicut game. Various levels of increasing difficulty are available.
Every year, millions of new scientific articles are published. With this growing volume of knowledge, it becomes increasingly important to have tools that make it easier to access relevant information. This is exactly where SQuAI comes in: the tool uses AI to answer scientific questions by searching relevant research articles and summarizing the most important information in a clear and accessible way. SQuAI places a strong emphasis on the verifiability of AI-generated content by providing citations within its answers and direct access to the referenced text passages from the original articles. This makes it transparent how an answer is constructed and on which scientific evidence it is based. As a result, SQuAI is not only informative but also promotes transparency and facilitates access to up-to-date research.
Since 2024, NAIC has been developing an AI chatbot for female students in STEM fields. So far, the focus has been on AI-based coaching and skill development. The project has shown that many questions from students are very specific. What deadline applies to me? What does this section of the examination regulations mean? What’s my next step? That’s why we’re now shifting our focus more toward academic organization and document comprehension. Going forward, Metis will help make academic and examination regulations easier to understand, help students keep track of deadlines, and help them derive concrete steps to take from complex documents.


Dresden Science Night 2026
On June 26, 2026, our Living Lab opened its doors for Dresden Science Night 2026.Throughout the evening, visitors explored AI through hands-on demonstrations and conversations with researchers. Families, students, and technology enthusiasts joined us to discover how AI works and why it matters. Today, many people use AI without even noticing it. However, the technology can still feel complex. That is why Dresden Science Night 2026 focused on simple explanations, direct interaction, and open dialogue. Instead of only talking about research, we invited visitors to experience it themselves. As a result, our Living Lab became a place for learning, discussion, and discovery. Besides asanAI, the Multicut Game and SQuAI, which had already been presented at OUTPUT.DD 2026, we also showcased a number of other inspring demos at Dresden Science Night 2026.
The Magic Mirror is an interactive system that allows you to try on clothes virtually. By combining image and voice processing, you can select items of clothing and see them directly in your own reflection. Visitors stood in front of a life-size screen with an integrated camera that showed a real-time image of their appearance. They used voice commands to specify the desired garments, which were then digitally projected onto their reflection. This intuitive experience makes trying on clothes more comfortable and offers an innovative way to try out different styles and outfits without having to actually change clothes. It also offers a great possiblity to talk about bias in data sets. Furthermore, the mirror reveals how (generative) AI works, clarifies algorithmic choices, and exposes stereotypical outputs.
We introduced Chatopia: a digital platform that creates a virtual world where hundreds of AI agents interact, socialize, and learn from one another simultaneously – much like watching an entire simulated society unfold, rather than chatting with a single chatbot. Chatopia works like a flight simulator for AI: Scientists can safely train AI systems and test complex social scenarios at computer speed (in minutes or hours) instead of waiting years for real-world results. This makes experiments faster, cheaper, and risk-free.
In the LLMpedia project, researchers generate and evaluate encyclopedia-style articles directly from a model’s parametric memory, making it possible to study what the model knows beyond fixed benchmarks. Large language models have become everyday knowledge interfaces for millions of users. However, their real factual reliability in open-ended writing is still not well understood. Existing benchmarks rely on small, pre-selected sets of questions, which can create an availability bias: they may overestimate factuality by only measuring what evaluators expected to ask. LLMpedia addresses this problem by letting models write full encyclopedic articles from memory only, without retrieval, and then systematically verifying the generated claims. As a large-scale study, LLMpedia generated around 1 million articles across three model families.
The results show that the benchmark picture is incomplete: for gpt-5-mini, the verifiable true rate on Wikipedia-covered subjects is 74.7%, more than 15 percentage points below the 90%+ impression suggested by benchmark-style evaluation. For frontier subjects that can only be verified through curated web evidence, the true rate drops further to 63.2%.
LLMpedia makes two main contributions. First, it offers a new way to study what LLMs know, how they express that knowledge in free text, and where their factual limits lie. Second, it provides the first fully open parametric encyclopedia framework, with all prompts, artifacts, and evaluation verdicts publicly released, enabling transparent and reproducible research at scale.
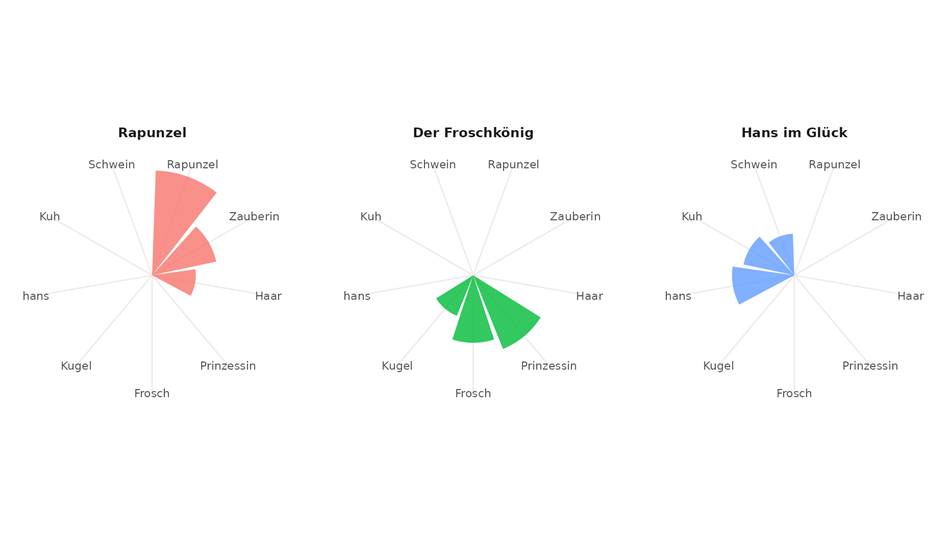
What facts do large language models believe in? chatGPT and co. are impressive in many applications, but what facts are their answers based on? In the GPTKB project, researchers extract and visualize massive amounts of facts from large language models.
Large language models (LLMs) have greatly advanced AI and natural language processing (NLP). In addition to their ability to perform many different tasks, their great success lies in the fact that they have a lot of factual knowledge. For years, researchers have always been interested in how much these models really “know”, but previous methods only work with small, pre-selected data, which leads to an “availability bias” (Tversky and Kahneman), meaning that researchers often only discover what they already expected – and may miss a lot.
To solve this problem, we have developed a new method with which we can systematically and comprehensively capture the knowledge of an LLM. To do this, we ask it many questions and intelligently summarize the answers.
As a test run, we used GPT-4o-mini to create GPTKB – a huge collection of knowledge with 101 million facts about 2.9 million subjects. Best of all, we did the whole thing for just 1% of the cost of previous projects!
GPTKB is a significant step forward in two areas: First, it helps to better understand how LLMs “think” and what facts they know. Secondly, it shows new, efficient ways to create large knowledge collections.
Language models like ChatGPT have read billions of texts about cities, traffic, and mobility, but how much of it have they actually retained? In project C6 (AgiMo / CRC TRR 408) we explore whether Large Language Models can support transportation planning. We showed what an AI thinks it knows about Dresden: where it gets things right, where it confidently makes things up, and where its real limits lie.
How can language be made understandable to computers? We showcased how words are translated into numbers and how this can be used to calculate differences, similarities, and meanings. This forms the basis for how today’s language models – such as ChatGPT or automatic translators – can analyze, complete, or respond to texts.


Conversations Beyond Technology
Throughout both events, visitors discussed language models, ethics, trust, and the future of AI with our researchers. Some guests arrived with excitement. Others arrived with questions or concerns. Yet everyone contributed to thoughtful and engaging discussions. These exchanges reminded us that science communication is about more than sharing knowledge. It is also about listening, learning, and building connections.
Outlook
Events such as OUTPUT.DD 2026 and Dresden Science Night 2026 create opportunities for people to engage directly with science. Visitors can ask questions, challenge ideas, and gain insights into current research. At the same time, researchers can learn more about public interests and concerns. This exchange is valuable for everyone. Therefore, public engagement remains an important part of our mission. We would like to thank everyone who visited our Living Lab. Your curiosity, enthusiasm, and thoughtful questions made both events very memorable. We hope you enjoyed exploring AI with ScaDS.AI Dresden/Leipzig. Until next time, stay curious and keep exploring.



funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
