
LLMpedia
Title: LLMpedia: A Transparent Framework to Materialize an LLM’s Encyclopedic Knowledge at Scale
Project duration: started in 2026
Research Area: Understanding Language, Knowledge Representation and Engineering

LLMpedia is a large-scale encyclopedia generated entirely from the parametric memory of large language models – without any retrieval from external sources. Structured as an interlinked resource analogous to Wikipedia, it produces close to one million articles across three model families (GPT-5-mini, DeepSeek-V3.2, Llama 3.3-70B). The project introduces a scalable, open-source pipeline covering article planning, dynamic outline generation, and a three-stage entity sanitization pipeline.
Controlled experiments show that simple prompt-level persona injection measurably shifts political framing across generated content at scale. LLMpedia also enables a novel way to benchmark LLM knowledge. For GPT-5-mini, the verifiable true rate on Wikipedia-covered subjects is 74.7% – more than 15 points below what previous benchmarks suggest. LLMpedia is fully open: all data, code, prompts, and evaluation verdicts are public.
Aims
LLMpedia bridges factuality evaluation and knowledge materialization into a single framework. It aims to:
- Produce a transparent, reproducible dataset for NLP research
- Expose the gap between benchmark accuracy and real-world open-ended factuality
- Develop scalable methods for parametric encyclopedia construction
- Study how editorial framing through prompt design shapes AI-generated content at scale
Problem
The benchmark accuracy figure most people quote for frontier LLMs is not the accuracy you get in the wild. LLMpedia proves it – at scale, with over one million open-ended articles.
Standard benchmarks such as MMLU report 90%+ factual accuracy for frontier LLMs – a headline figure widely used to claim near-human reliability. But these benchmarks test only the knowledge evaluators thought to ask about, creating availability bias: models appear highly factual on a fixed question set while vast regions of their knowledge remain untested.
LLMpedia breaks that assumption by eliciting knowledge across nearly one million topics in free-text form – the format real users actually receive. The results are sobering:
| Evaluation Setting | Accuracy | vs. MMLU | Source |
|---|---|---|---|
| Benchmark (MMLU / HLE) | ~90% | – | Published |
| Wikipedia-Covered Subjects (LLMpedia) | 74.7% | −15.3 pp | LLMpedia |
| Frontier Subjects (absent from Wikipedia) | 63.2% | −26.8 pp | LLMpedia |
The gap is not a rounding error – it is structural. Fixed-question benchmarks overstate open-ended factual reliability because they test only what the evaluator thought to ask. LLMpedia surfaces the full picture: Wikipedia covers just 61% of entities the model itself surfaces, and three model families share only 7.3% of their subjects – confirming that materialized knowledge is far more model-specific than leaderboard scores suggest.
Key finding: Moving from MMLU-style benchmarks to open-ended encyclopedic evaluation reveals a 15-point accuracy drop on familiar topics and nearly 27 points on frontier subjects. This is the availability bias at scale – and LLMpedia is the first framework to quantify it systematically.
Practical Example
LLMpedia is publicly browsable. Users can explore AI-generated encyclopedia articles on topics from cities like Dresden to historical figures. It serves as a research corpus for studying factuality, knowledge coverage, retrieval behavior, and editorial bias in LLM-generated content – and as a transparent counterpart to opaque systems such as Grokipedia.
Technology
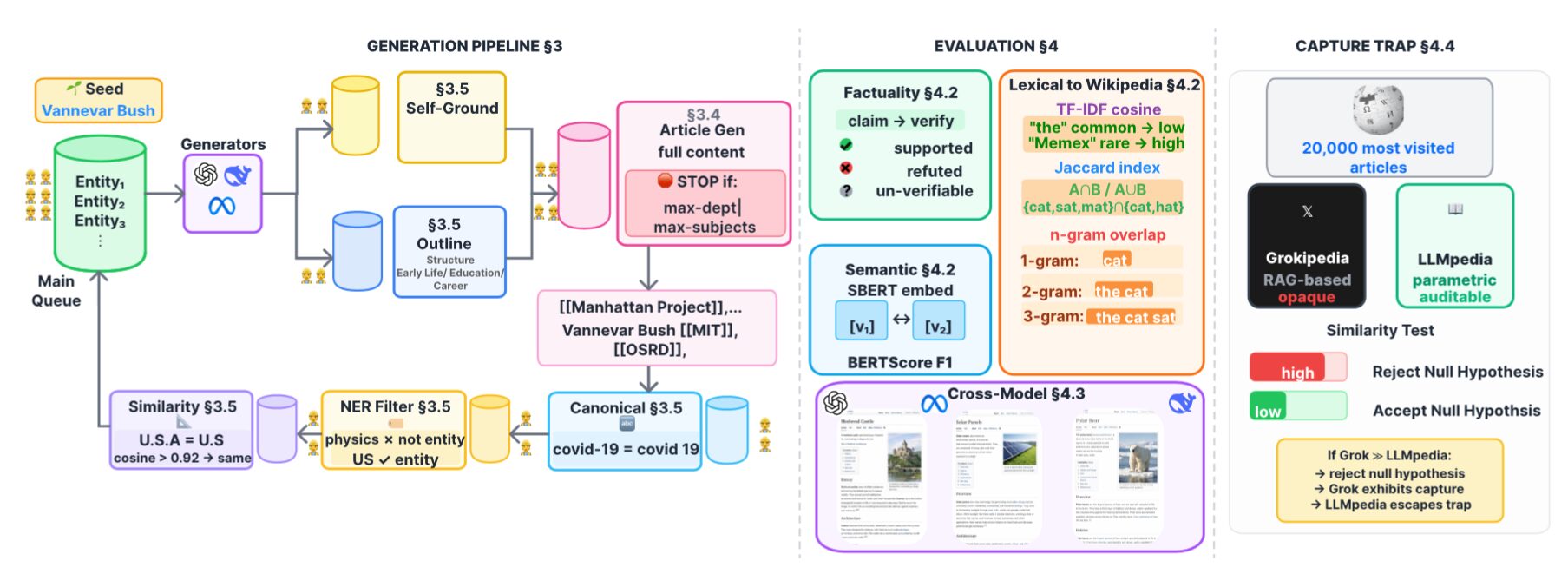
LLMpedia uses a breadth-first search (BFS) pipeline seeded from a single entity (Vannevar Bush for general-domain runs) that expands by generating Wikipedia-style articles in Wikitext and extracting [[wikilinks]] as the next frontier. Every article passes through three stages:
- Optional self-grounding to produce a structured fact sheet
- Dynamic outline generation with 6–7 entity-tailored section headings
- Full article elicitation in the free-text modality users see
Extracted wikilink candidates undergo a three-stage sanitization pipeline: canonical normalization (Unicode NFKC, case-folding), LLM-based named-entity filtering to remove generic terms, and embedding-based deduplication (text-embedding-3-small, cosine threshold 0.90) with LLM arbitration for borderline cases. Editorial personas (scientific-neutral, left-leaning, conservative) are injected at the system level of every pipeline stage. Automatic factuality evaluation uses gpt-4.1-nano to extract and verify up to ten atomic claims per article against Wikipedia (Tier 1) and curated web evidence (Tier 2). All runs use temperature 0 with fixed seeds.
Outlook
LLMpedia opens several research directions:
- Tracking how encyclopedic LLM knowledge evolves across model generations
- Analyzing embedded editorial biases at scale
- Exploring how parametric knowledge can complement Wikipedia (~39% of surfaced entities are absent from it)
- Multilingual expansion and factuality-aware generation
- Deeper hop-stratified analysis and integration with knowledge graph pipelines
LLMpedia provides a reproducible, transparent baseline for benchmarking AI-generated encyclopedic resources against academic standards of openness – a contrast that matters given the opacity of comparable systems currently in public use.
Publications
- Muhammed Saeed and Simon Razniewski. “LLMpedia: A Transparent Framework to Materialize an LLM’s Encyclopedic Knowledge at Scale.” arXiv:2603.24080, 2025. https://arxiv.org/abs/2603.24080
- Yujia Hu, Tuan-Phong Nguyen, Shrestha Ghosh, and Simon Razniewski. Enabling LLM Knowledge Analysis via Extensive Materialization. ACL, 2025
Team
Lead
Team Members
- Muhammed Saeed

Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
