
April 23, 2026
ScaDS.AI Dresden/Leipzig at ACM CHI 2026 in Barcelona, Spain
ScaDS.AI Dresden/Leipzig
The ACM (Association for Computing Machinery) CHI conference on Human Factors in Computing Systems, which is the leading international conference on Human-Computer Interaction, took place in Barcelona from April 13 to 17, 2026. Submissions to this year’s program were accepted in the submission areas: posters, papers, interactive demos, panels, workshops and meetups.
Once again this year, we at ScaDS.AI Dresden/Leipzig are proud that so many of our researchers were able to present and discuss their work at the conference.
Researchers from the center contributed to the conference with 5 full papers (1 Honorable Mention Award), 7 posters, and 3 workshop papers. These are the contributions that were presented as part of the conference program:
ScaDS.AI papers at CHI 2026
We congratulate the authors of the paper “Log2Motion: Biomechanical Motion Synthesis from Touch Logs” for receiving a Honorable Mention Award. The award recognizes outstanding papers and highlights exceptional research quality, representing the top 5% of the conference submissions.
Read more about the AI model Log2motion in the article “Tired of swiping? An AI simulation helps us understand why” on our blog.


The overall acceptance rate for the papers track was 25.3% of completed submissions.
Below are the titles, authors, DOIs, and abstracts of all the papers presented:
Beyond Links: Exploring Visual Representations of Multi-View Relations in Mixed Reality
Authors: Weizhou Luo, Rufat Rzayev, Benjamin Russig, Sivanon Visutarporn, Marc Satkowski, Stefan Gumhold, Raimund Dachselt
DOI: https://doi.org/10.1145/3772318.3791398
This paper investigates associations, explicit representations of relations between multiple views in Mixed Reality (MR). While research on 2D desktop environments offers extensive recommendations for communicating relations between multiple views, MR environments lack such systematic guidance, necessitating adapted solutions that consider their spatial affordances. To address this gap, we systematically explored association techniques in existing research. Building on established 2D multi-view literature and refining insights from prior design principles, we developed a codebook to describe view relations and their representations. Applying it to a corpus of 44 immersive multi-view approaches, we identified recurring design strategies and synthesized them into a design space of visual association techniques adapted for immersive contexts. Based on a lightweight prototyping framework, we validate the utility of the design space through three envisioning scenarios, demonstrating how associations can support exploration, coordination, and sensemaking in MR applications. Our results inform the design of MR multi-view environments.
GTA: Generative Traffic Agents for Simulating Realistic Mobility Behavior
Authors: Simon Lämmer, Mark Colley, Patrick Ebel
DOI: https://doi.org/10.1145/3772318.3790772
People’s transportation choices reflect complex trade-offs shaped by personal preferences, social norms, and technology acceptance. Predicting such behavior at scale is a critical challenge with major implications for urban planning and sustainable transport. Traditional methods use handcrafted assumptions and costly data collection, making them impractical for early-stage evaluations of new technologies or policies. We introduce Generative Traffic Agents (GTA) for simulating large-scale, context-sensitive transportation choices using LLM-powered, persona-based agents. GTA generates artificial populations from census-based sociodemographic data. It simulates activity schedules and mode choices, enabling scalable, human-like simulations without handcrafted rules. We evaluate GTA in Berlin-scale experiments, comparing simulation results against empirical data. While agents replicate patterns, such as modal split by socioeconomic status, they show systematic biases in trip length and mode preference. GTA offers new opportunities for modeling how future innovations, from bike lanes to transit apps, shape mobility decisions.
Helping Johnny Make Sense of Privacy Policies with LLMs
Authors: Vincent Freiberger, Arthur Fleig, Erik Buchmann
DOI: https://doi.org/10.1145/3772318.3791465
Understanding and engaging with privacy policies is crucial for online privacy, yet these documents remain notoriously complex and difficult to navigate. We present PRISMe, an interactive browser extension that combines LLM-based policy assessment with a dashboard and customizable chat interface, enabling users to skim quick overviews or explore policy details in depth while browsing. We conduct a user study (N=22) with participants of diverse privacy knowledge to investigate how users interpret the tool’s explanations and how it shapes their engagement with privacy policies, identifying distinct interaction patterns. Participants valued the clear overviews and conversational depth, but flagged some issues, particularly adversarial robustness and hallucination risks. Thus, we investigate how a retrieval-augmented generation (RAG) approach can alleviate issues by re-running the chat queries from the study. Our findings surface design challenges as well as technical trade-offs, contributing actionable insights for developing future user-centered, trustworthy privacy policy analysis tools.
Log2Motion: Biomechanical Motion Synthesis from Touch Logs
Authors: Michał Patryk Miazga, Hannah Bussmann, Antti Oulasvirta, Patrick Ebel
DOI: https://doi.org/10.1145/3772318.3790773
Touch data from mobile devices are collected at scale but reveal little about the interactions that produce them. While biomechanical simulations can illuminate motor control processes, they have not yet been developed for touch interactions. To close this gap, we propose a novel computational problem: synthesizing plausible motion directly from logs. Our key insight is a reinforcement learning-driven musculoskeletal forward simulation that generates biomechanically plausible motion sequences consistent with events recorded in touch logs. We achieve this by integrating a software emulator into a physics simulator, allowing biomechanical models to manipulate real applications in real-time. Log2Motion produces rich syntheses of user movements from touch logs, including estimates of motion, speed, accuracy, and effort. We assess the plausibility of generated movements by comparing against human data from a motion capture study and prior findings, and demonstrate Log2Motion in a large-scale dataset. Biomechanical motion synthesis provides a new way to understand log data, illuminating the ergonomics and motor control underlying touch interactions.
Mixed Presence in Mixed Reality: Charting the Challenges and Opportunities
Authors: Katja Krug, Wolfgang Büschel, Marc Satkowski, Stefan Gumhold, Raimund Dachselt
DOI: https://doi.org/10.1145/3772318.3791508
This paper investigates the challenges of designing mixed-presence environments for Mixed Reality and suggests future research directions derived from an expert workshop. Developing mixed-presence systems is a complex undertaking that combines the intricacies of both co-located and distributed mixed-reality spaces. Current literature in this field describes various promising design and development approaches but lacks a systematic overview, resulting in fragmented solutions to re-occurring challenges. Therefore, we conducted a comprehensive review of mixed-presence and multi-user remote mixed-reality systems, categorizing the prevalent challenges faced during the development of such systems, but also current trends, common use cases, study tasks and methodologies. Supported by these results, we then conducted an expert ideation workshop to collect and structure promising future research directions. As a result, we provide a detailed resource to orient and prepare developers for probable challenges and support researchers in making informed design decisions for future mixed-presence studies in Mixed Reality.
ScaDS.AI posters at CHI 2026
The poster sessions were spread out over four afternoons during the conference, and topics from our researchers were presented at each of these sessions.
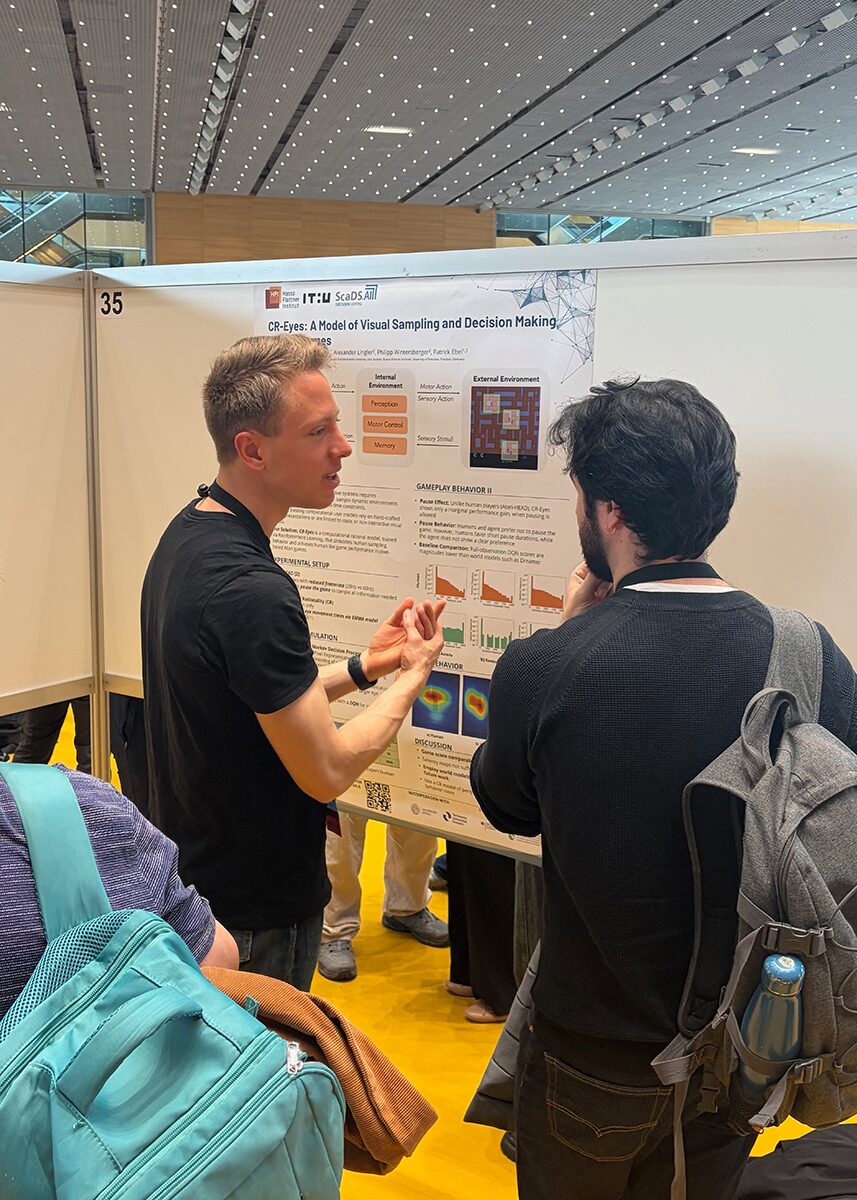




CR-Eyes: A Model of Visual Sampling and Decision Making in Atari Games
Authors: Martin Lorenz, Niko Konzack, Alexander Lingler, Philipp Wintersberger, Patrick Ebel
DOI: https://doi.org/10.1145/3772363.3798498
Designing mobile and interactive technologies requires understanding how users sample dynamic environments to acquire information and make decisions under time pressure. However, existing computational user models either rely on hand-crafted task representations or are limited to static or non-interactive visual inputs, restricting their applicability to realistic, pixel-based environments.
We present CR-Eyes, a computationally rational model that simulates visual sampling and gameplay behavior in Atari games. Trained via reinforcement learning, CR-Eyes operates under perceptual and cognitive constraints and jointly learns where to look and how to act in a time-sensitive setting. By explicitly closing the perception–action loop, the model treats eye movements as goal-directed actions rather than as isolated saliency predictions. Our evaluation shows strong alignment with human data in task performance and aggregate saliency patterns, while also revealing systematic differences in scanpaths. CR-Eyes is a step toward scalable, theory-grounded user models that support design and evaluation of interactive systems.
MRDrive: An Open Source Mixed Reality Driving Simulator for Automotive User Research
Authors: Patrick Ebel, Michał Patryk Miazga, Martin Lorenz, Timur Getselev, Pavlo Bazilinskyy, Celine Conzen
DOI: https://doi.org/10.1145/3772363.3799273
Designing and evaluating in-vehicle interfaces requires experimental platforms that combine ecological validity with experimental control. Driving simulators are widely used for this purpose. However, they face a fundamental trade-off: high-fidelity physical simulators are costly and difficult to adapt, while virtual reality simulators provide flexibility at the expense of physical interaction with the vehicle.
In this work, we present MRDrive, an open mixed-reality driving simulator designed to support HCI research on in-vehicle interaction, attention, and explainability in manual and automated driving contexts. MRDrive enables drivers and passengers to interact with a real vehicle cabin while being fully immersed in a virtual driving environment. We demonstrate the capabilities of MRDrive through a small pilot study that illustrates how the simulator can be used to collect and analyze eye-tracking and touch interaction data in an automated driving scenario. https://github.com/ciao-group/mrdrive.
MyoInteract: Fast and Usable Reinforcement Learning for Biomechanical Simulations in HCI
Authors: Ankit Bhattarai, Hannah Selder, Florian Fischer, Arthur Fleig, Per Ola Kristensson
DOI: https://doi.org/10.1145/3772363.3798381
Biomechanical reinforcement learning (RL) can be used to simulate muscle-actuated user movements during interaction, offering enormous potential for prototyping ergonomic and accessible interfaces. Existing frameworks, however, require 12-48 hours of training, as well as substantial expertise in RL and biomechanics, which makes these frameworks inaccessible to most HCI researchers. We present MyoInteract, a framework for fast and usable simulation of biomechanical HCI tasks. MyoInteract reduces RL training times by up to 99% by leveraging GPU-accelerated physics, and offers a GUI to configure tasks, run trainings, and monitor learned behaviour. A workshop involving 12 HCI researchers, most of them novices in biomechanical RL, found that they could all configure and train simulated users within a single two-hour session. By overcoming previous speed issues and lowering entry barriers, MyoInteract transforms biomechanical RL from an expert-only endeavour into a fast and usable method for simulating interactive user behaviour.
ST-Buddy: Designing and Evaluating a Course-Grounded LLM Chatbot for Academic and Administrative Support
Authors: Chrakhan Barzanji, Niclas Rosteck, Sebastian Eberl, Sebastian Rottmann, Claudia Loitsch
DOI: https://doi.org/10.1145/3772363.3798558
Understaffed universities and limited funding for tutors risk students’ disengagement due to missing assistance. HCI research increasingly focuses on conversational agents for scalable educational support. This paper presents a course-specific AI chatbot designed to answer students’ questions and reduce tutor workload by addressing frequent organizational and content-related questions. Developed as a pilot case study for an introductory Software Technology course, ST-Buddy combines modular LLM-based dialogue with a flexible course-grounded knowledge integration to enable adaptive, context-aware responses grounded in relevant course material and logistical information. A formative evaluation of ST-Buddy (n=32) showed good usability (SUS=77.81), perceived helpfulness particularly when tutors were unavailable, and rated response quality as relevant and understandable. Additionally, students’ self-reported everyday academic AI use and lessons learned from the evaluation settings are discussed. These findings outline implications for improving future evaluations and highlight the potential of modular chatbot frameworks to scale personalized support in large courses.
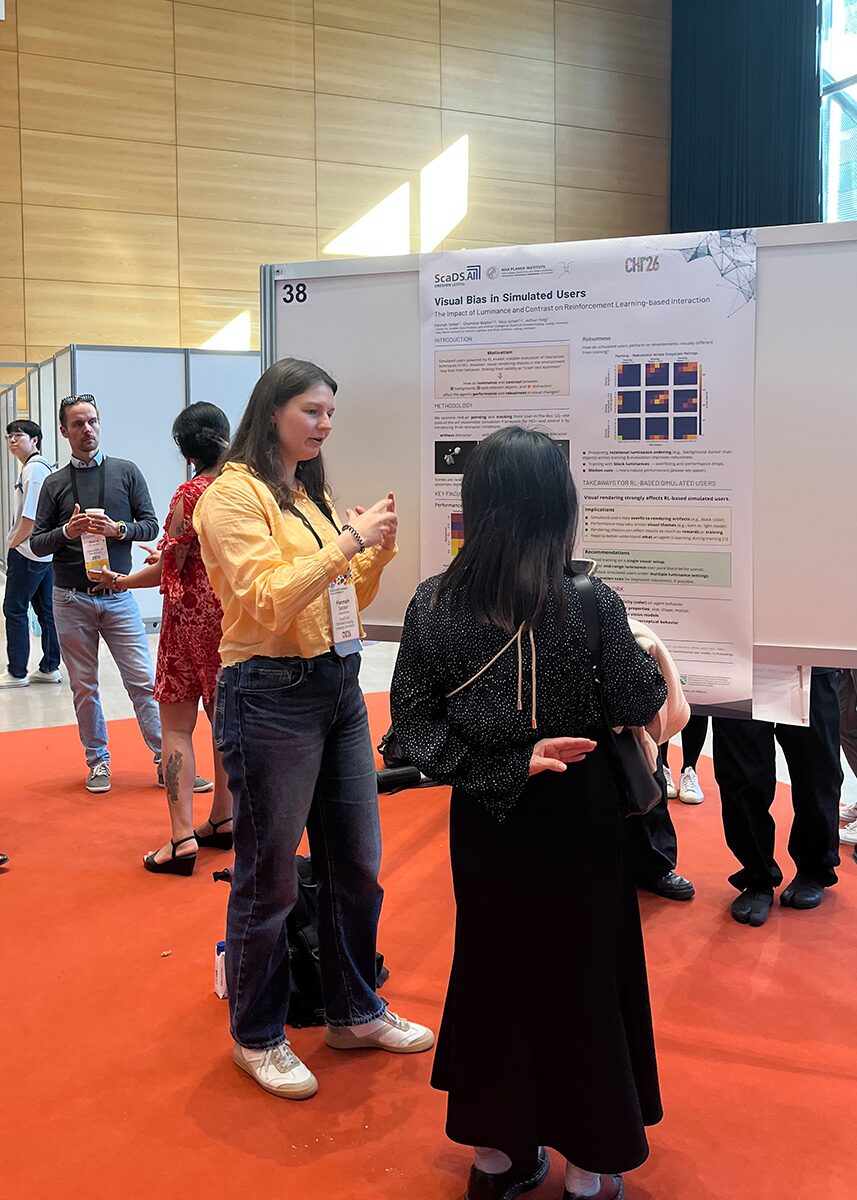
Visual Bias in Simulated Users: The Impact of Luminance and Contrast on Reinforcement Learning-based Interaction
Authors: Hannah Selder, Charlotte Beylier, Nico Scherf, Arthur Fleig
DOI: https://doi.org/10.1145/3772363.3798826
Reinforcement learning (RL) enables simulations of HCI tasks, yet their validity is questionable when performance is driven by visual rendering artifacts distinct from interaction design. We provide the first systematic analysis of how luminance and contrast affect behavior by training 247 simulated users using RL on pointing and tracking tasks. We vary the luminance of task-relevant objects, distractors, and background under no distractor, static distractor, and moving distractor conditions, and evaluate task performance and robustness to unseen luminances. Results show luminance becomes critical with static distractors, substantially degrading performance and robustness, whereas motion cues mitigate this issue. Furthermore, robustness depends on preserving relational ordering between luminances rather than matching absolute values. Extreme luminances, especially black, often yield high performance but poor robustness. Overall, seemingly minor luminance changes can strongly shape learned behavior, revealing critical insights into what RL-driven simulated users actually learn.
Who Explains Privacy Policies to Me? Embodied and Textual LLM-Powered Privacy Assistants in Virtual Reality
Authors: Vincent Freiberger, Moritz Dresch, Florian Alt, Arthur Fleig, Viktorija Paneva
DOI: https://doi.org/10.1145/3772363.3798567
Virtual Reality (VR) systems collect fine-grained behavioral and biometric data, yet privacy policies are rarely read or understood due to their complex language, length, and poor integration into users’ interaction workflows. To lower the barrier to informed consent at the point of choice, we explore a Large Language Model (LLM)-powered privacy assistant embedded into a VR app store to support privacy-aware app selection. The assistant is realized in two interaction modes: a text-based chat interface and an embodied virtual avatar providing spoken explanations. We report on an exploratory within-subjects study (𝑁 = 21) in which participants browsed VR productivity applications under unassisted and assisted conditions. Our findings suggest that both interaction modes support more deliberate engagement with privacy information and decision-making, with privacy scores primarily functioning as a veto mechanism rather than a primary selection driver. The impact of embodied interaction varied between participants, while textual interaction supported reflective review.
Who Will Fix This? Roles for IT-Security Incident Response in the Smart Home
Authors: Victor Jüttner, Arthur Fleig, Erik Buchmann
DOI: https://doi.org/10.1145/3772363.3799356
Smart homes face a growing range of cybersecurity incidents, from external device compromise to internal misuse by household members with legitimate access. Responding to such incidents is challenging because smart homes are multi-user environments with individuals differing in access, expertise, and vulnerability, and the source of harm may be someone inside the home. In this work, we systematize roles relevant for incident response in smart homes through a systematic literature review of 22 studies in HCI and usable security. We identify key internal and external roles and analyze how responsibility, accountability, consultations, and information are shared during incidents. Our findings show that incident response in smart homes cannot be reduced to technical remediation by a single actor, but requires coordinating actions across overlapping roles. We discuss implications for HCI research and design, highlighting how role-aware incident response mechanisms can better account for affected household members.
Workshop contributions by ScaDS.AI
Three additional papers were submitted as position papers for CHI ’26 workshops:
Feel the story in your hands: Tangibles for exploring collaborative scientific storytelling
Authors: Susmita Khadse, Julian Baader, Clara Leidhold
Link to position paper
In this position paper, we propose that tangible objects, passive or active, can be used for scientific data storytelling. Tangible devices can convey data to users in a more collaborative manner, helping users feel connected to the task. This can foster knowledge transfer
and collaborative sensemaking and connect the user at an emotional level for data comprehension.
Flat No More: From Personal Screens to Shared Tangible Devices
Authors: Julian Baader, Susmita Khadse
Link to position paper
In this position paper, we propose a continuum of tangible interfaces, from tailored artifacts to everyday mobile devices. While mobile devices are tangible, their form factors reinforce individual use. Emerging multi-surface and non-planar devices (foldables, cubes, spheres) may change this, enabling shared use and supporting not only task collaboration but also relational micro-dynamics in co-located settings.
The Privacy Guardian Agent: Towards Trustworthy AI Privacy Agents
Author: Vincent Freiberger
The current “notice and consent” paradigm is broken: consent dialogues are often manipulative, and users cannot realistically read or understand every privacy policy. While recent LLM-based tools empower users seeking active control, many with limited time or motivation prefer full automation. However, fully autonomous solutions risk hallucinations and opaque decisions, undermining trust. I propose a middle ground — a Privacy Guardian Agent that automates routine consent choices using user profiles and contextual awareness while recognizing uncertainty. It escalates unclear or high-risk cases to the user, maintaining a human-in-the-loop only when necessary. To ensure agency and transparency, the agent’s reasoning on its autonomous decisions is reviewable, allowing for user recourse. For problematic cases, even with minimal consent, it alerts the user and suggests switching to an alternative site. This approach aims to reduce consent fatigue while preserving trust and meaningful user autonomy.Workshop: Moving Beyond Clicks: Rethinking Consent and User Control in the Age of AI



funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
