
April 14, 2026
Open Data for German Handwriting Recognition
ScaDS.AI Dresden/Leipzig
Automatic handwritten text recognition (HTR) is a challenging task, particularly in the context of the German language. While conventional optical character recognition (OCR) systems are highly sophisticated for printed text, handwriting exhibits significantly more complexity due to its high variability, overlaps, individual writing styles, and structural peculiarities.
In 2025, Ahamd Alzin, Till Nestler, and Thomas Burghardt therefore processed 775 handwritten Wikipedia transcripts using data science methods. Each transcript is half a DIN A4 page in length, consisting of about 15 lines and approximately 220 words. 775 anonymous writers from German-speaking regions generated The Wikipedia excerpts.
They extracted over 42,000 words and text lines as image data and made them available to researchers alongside the ground truth in the ScaDS.AI German Line- and Word-Level Handwriting Dataset. In addition, they added a second dataset named ScaDS.AI German Full-Page Handwriting Dataset and extracted 77 full-page handwritten pages from Wikipedia transcripts as image data and stored them alongside ground truth data.
Study
With their second dataset, the team conducted a benchmark study to examine and evaluate the recognition accuracy of large multimodal models (e.g., GPT-4o) on full-page handwriting. These are referred to as Vision Language Models (VLMs).
Structure
Optical character recognition (OCR) refers to the automated conversion of images containing printed or handwritten text into machine-readable data. It is one of the fundamental technologies of document digitization. Uses cases are diverse and range from sorting mail to industrial label inspection. Handwriting recognition is a subset of OCR because it focuses on handwritten text.
The literature indicates that large multimodal models (e.g., GPT-4), also known as end-to-end approaches, are becoming increasingly effective at recognizing Latin handwriting. These end-to-end approaches analyze image and context together within a single model and can thus directly account for semantic relationships. Computionally, they are more intensive though. Before these modern approaches were developed, handwriting was processed in several sequential individual steps.
- Text detection identifies the areas of an image that contain text.
- Text recognition converts the detected text regions into character strings. Popular open-source systems such as EasyOCR are available for this purpose.
Methodology
In their study, the team empirically evaluated the performance of the VLMs using the second dataset they created. Several VLMs are hosted and operated locally at ScaDS.AI Dresden/Leipzig:
- vllm-llama-4-scout-17b-16e-instruct (abbreviation in this paper: kiara_llama)
- Llama-4-Scout-17B-16E-Instruct (abbreviation in this paper: scads_llama)
- Qwen3-VL-8B-Instruct (abbreviation in this post: scads_qwen)
In addition, we included the model not hosted at our center in the study: - chatgpt-4o-latest (abbreviation in this post: openai_chatgpt40)
With these models, the prompt is submitted via the application programming interface (API). The prompt is: “Please output the entire text in the image. The response should contain only the recognized text.” In addition, image data – the digital copy of the Wikipedia transcript – is also sent to the model via the API. The model then returns the recognized text as a response. To evaluate the quality of the handwriting recognition, the team used relevant metrics:
- Character Error Rate (CER): measures the error rate at the character level by counting how many insertions, deletions, and replacements of characters are needed to convert the recognized text into the reference text.
- Word Error Rate (WER): measures the error rate at the word level, applying the same operations (insertion, deletion, replacement) to entire words.
Both metrics compare the recognized text with the reference text (ground truth) and divide the number of errors by the total number of characters or words in the reference text.
Results
CER/WER Comparison

CER is below 5 percent for all models, and WER is below 12 percent. In a direct comparison, the openai_chatgpt40 model achieves the lowest error rates (CER below 3%).
CER distribution across 77 manuscripts
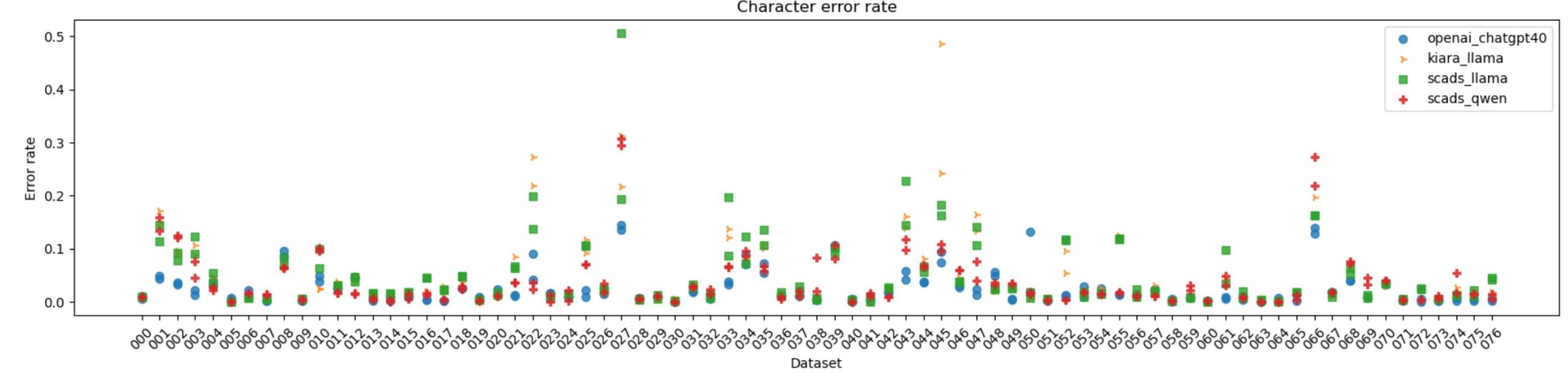
In the figure, the 77 manuscripts are shown horizontally and the error rates vertically. It can be seen that the CER error rate is not evenly distributed across all manuscripts. Some manuscripts perform significantly worse than others. Why is this the case?
Faulty digitized images and fragmented characters



The Manuscript 027 (titled “Croatian”) has significantly worse recognition values than manuscript 056.
Approximately 19 of the 77 manuscripts were not digitized correctly, and truncated characters are visible. For example, this happened on the left margin of manuscript 027. These errors were already present in the scans. If those 19 manuscripts are excluded, the CER improves by about 10%. Fragmented characters complicate segmentation and classification, e.g., letters with ink gaps (see Manuscript 027). The ChatGPT openai_chatgpt40 model produces comparatively robust results even with this manuscript, which is difficult for the human eye to read.
Continuous cursive writing leads to character merging, which allows for multiple interpretations. Blurred stroke contours caused by ink bleed can also lead to errors (see Handwriting 066).
There are other potential sources of error that are not addressed in this paper. This study should be understood as a preliminary study. Larger datasets are required to draw reliable conclusions.
Related Project
Since fall 2025, master’s student Jannes Nitzsche has been investigating two OCR approaches for extracting information from industrial product labels in his master’s thesis titled “Multimodal Approaches for Information Extraction from Industrial Product Labels.”
Master’s Thesis: Multimodal Approaches for Information Extraction from Industrial Product Labels
In addition to handwriting recognition, OCR is an important method for accurately recognizing characters (e.g., on product labels) in an industrial context. Jannes Nitzsche employed VLMs and classical OCR methods for text recognition. Jannes Nitzsche achieved the results in the course of the master’s thesis during his employment at Telekom MMS (Telekom MMS | Experience Beyond Digital). They were carried out in the context of the European funding project IPCEI-CIS (IPCEI-CIS – 8ra). The thesis was supervised by Thomas Burghardt.
Industrial labels contain key information:
- Product identifiers
- Batch numbers
- Safety information
- Certification details
Furthermore, additional challenges may arise in production environments:
- Soiled labels
- Poor print quality
- Light and shadow effects
- Computing power limitations
- Avoidance of powerful cloud solutions for data protection reasons
The study has shown that end-to-end approaches using VLMs achieve slightly better accuracy than traditional OCR methods. However, the latter are significantly faster and more resource-efficient. They tested the models using synthetic labels. There is no single best solution for character and text recognition. The choice of model always depends on the specific use case. Decision criteria include accuracy, speed, hardware, and data protection requirements.
Conclusion
- German handwriting samples are valuable for research in the field of handwriting recognition.
- Multimodal language models (VLMs) show surprisingly robust results for Latin handwriting.
- Data quality (scan quality, cropping) influences performance in handwriting recognition.
- The choice of recognition system (classical OCR systems or end-to-end approaches) is context-dependent.
Literature and Further Resources
Both datasets are published on Zenodo. They are available to researchers and can be used for training and evaluation purposes in the field of handwriting recognition.
- Dataset 1: ScaDS.AI German Line- and Word-Level Handwriting Dataset
- Dataset 2: ScaDS.AI German Full-Page Handwriting Dataset
- Dataset 3: Industrial Label Dataset for Structured Information Extraction
- Demonstrator: HTR Viewer
- EasyOCR
This article was written by Thomas Burghardt, Director of ScaDS.AI Living Lab Leipzig and edited by the ScaDS.AI Dresden/Leipzig communications department.



funded by:

ScaDS.AI Dresden/Leipzig (Center for Scalable Data Analytics and Artificial Intelligence) is a center for Data Science, Artificial Intelligence and Big Data with locations in Dresden and Leipzig.
Dresden
Visitor address
Technische Universität Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
ScaDS.AI Dresden/Leipzig
Bürogebäude Strehlener Straße
Strehlener Straße 12, 14
01069 Dresden
Postal address
Technische Universität Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Zentrum für Informationsdienste und Hochleistungsrechnen
ScaDS.AI Dresden/Leipzig
01062 Dresden
Leipzig
Visitor address
ScaDS.AI Dresden/Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Löhrs Carré
Humboldtstraße 25, Uferstr. 11
04105 Leipzig
Postal address
Universität Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Data Science Center ScaDS.AI Leipzig
Internes Postfach: 322001
04081 Leipzig
Quicklinks:
Copyright 2026 © SCADS.AI Dresden/Leipzig – All rights reserved.
